¿Qué Significa el Fine-tuning Completo?
Has descargado un modelo pre-entrenado — miles de millones de parámetros, meses de cómputo, terabytes de texto. Puede escribir código, resumir artículos y traducir entre idiomas. Pero necesitas que haga algo específico: clasificar cláusulas legales, generar reportes de radiología, o chatear en un tono particular. ¿Cómo transformas todo ese conocimiento general en un especialista?
La respuesta más directa es el fine-tuning completo : tomar el modelo pre-entrenado completo y continuar entrenándolo en tu dataset específico de la tarea, actualizando cada uno de los parámetros . No se congelan capas, no se insertan adaptadores, no se excluyen parámetros. Cada peso en cada capa es libre de moverse. Esta es la línea base conceptual — la forma más simple de adaptación de modelos, y contra la cual cada método de eficiencia de parámetros es finalmente medido.
El procedimiento es engañosamente simple. Partimos de los pesos pre-entrenados $\theta_0$, ejecutamos descenso de gradiente en nuestro dataset de fine-tuning $\mathcal{D}$, y llegamos a nuevos pesos $\theta^*$. Formalmente:
Descompongamos esto pieza por pieza. $\theta_0$ es el conjunto completo de pesos pre-entrenados — todo lo que el modelo aprendió durante el pre-entrenamiento. $\eta$ es la tasa de aprendizaje, que controla qué tan grande es cada paso de actualización. $\mathcal{D}$ es nuestro dataset de fine-tuning de pares entrada-salida $(x, y)$. $\nabla_\theta \mathcal{L}(x, y; \theta)$ es el gradiente de la función de pérdida respecto a los pesos — la dirección en la que los pesos necesitan moverse para reducir la pérdida en el ejemplo $(x, y)$. La suma acumula gradientes a través de todos los ejemplos (en la práctica usamos mini-batches, pero la idea es la misma).
El detalle crítico es que partimos de $\theta_0$, no de una inicialización aleatoria. Si inicializáramos aleatoriamente, estaríamos entrenando desde cero — todo el conocimiento que el modelo adquirió durante el pre-entrenamiento (sintaxis, hechos, patrones de razonamiento) se perdería. Partir de $\theta_0$ significa que heredamos ese conocimiento y solo necesitamos empujar los pesos hacia nuestra tarea específica. Esta es toda la propuesta de valor del fine-tuning: meses de pre-entrenamiento destilados en un punto de partida, y unas pocas horas de entrenamiento específico de la tarea encima.
Este enfoque fue formalizado y escalado por (Howard & Ruder, 2018) con ULMFiT, y luego se convirtió en el paradigma estándar con BERT (Devlin et al., 2019) y GPT (Radford et al., 2018) . Hoy, el fine-tuning completo sigue siendo el estándar de oro cuando la calidad importa y el cómputo está disponible. Pero "el cómputo está disponible" está haciendo mucho trabajo pesado en esa oración. Veamos por qué.
La Barrera de Memoria
El fine-tuning completo es conceptualmente simple, pero es costoso. El cuello de botella no es el tiempo (el entrenamiento a menudo converge en 1–3 épocas) sino la memoria . Para entender por qué, contemos los bytes.
Los LLMs modernos se entrenan con entrenamiento de precisión mixta usando el optimizador AdamW . Para un modelo con $N$ parámetros, esto es lo que necesita residir en la memoria de la GPU simultáneamente:
- Pesos del modelo (FP16): $2N$ bytes. Cada parámetro se almacena como un float de 16 bits (2 bytes).
- Gradientes (FP16): $2N$ bytes. Un gradiente por parámetro, también en media precisión.
- Estados del optimizador (FP32): $12N$ bytes. AdamW mantiene tres buffers FP32: una copia maestra de los pesos ($4N$), el primer momento / media móvil de gradientes ($4N$), y el segundo momento / varianza móvil de gradientes ($4N$). Estos deben estar en precisión completa para estabilidad numérica.
Sumando:
Son $16N$ bytes solo para pesos, gradientes y estado del optimizador — antes de siquiera contar las activaciones. Hagámoslo concreto. LLaMA-7B tiene $N = 7 \times 10^9$ parámetros. Sustituyendo: $16 \times 7 \times 10^9 = 112 \times 10^9$ bytes $= 112$ GB. Una GPU NVIDIA A100 — la bestia de carga para entrenamiento de LLMs — tiene 80 GB de VRAM. Ni siquiera podemos meter el estado de entrenamiento de un modelo de 7B en una sola A100. Y este es un modelo "pequeño" para los estándares de 2025.
Pero no hemos terminado. Durante el paso forward, también necesitamos almacenar activaciones intermedias — las salidas de cada capa — porque la retropropagación las necesita para calcular gradientes. La memoria de activaciones para un transformer escala como:
donde $s$ es la longitud de secuencia (número de tokens por ejemplo), $b$ es el tamaño de batch (número de ejemplos procesados juntos), $d$ es la dimensión oculta (ancho de cada capa), $L$ es el número de capas del transformer, y $k$ es una constante que captura bytes por elemento (aproximadamente 10–14, dependiendo de detalles de la arquitectura como el número de cabezas de atención y si almacenamos matrices de atención). La idea clave es que esto crece linealmente tanto con la longitud de secuencia como con el tamaño de batch — las dos dimensiones que más quisiéramos aumentar.
Para un modelo de 7B ($s = 2048, b = 1, d = 4096, L = 32, k \approx 12$), esto da aproximadamente $2048 \times 1 \times 4096 \times 32 \times 12 \approx 3.2 \times 10^9$ bytes, o alrededor de 3 GB. Manejable para batch size 1, pero escala el batch a 8 y agregas otros 22 GB. Cada dimensión multiplica.
El código a continuación calcula el requisito total de memoria (pesos + gradientes + optimizador + activaciones) para tres tamaños de modelo. Observa qué rápido los números exceden lo que cabe en una sola GPU.
import json, js
models = [
{"name": "LLaMA-7B", "N": 7e9, "d": 4096, "L": 32, "s": 2048},
{"name": "LLaMA-13B", "N": 13e9, "d": 5120, "L": 40, "s": 2048},
{"name": "LLaMA-70B", "N": 70e9, "d": 8192, "L": 80, "s": 2048},
]
rows = []
for m in models:
N = m["N"]
# Weights (FP16) + Gradients (FP16) + Optimizer (FP32: master + m1 + m2)
param_mem_gb = (16 * N) / 1e9
# Activation memory: s * b * d * L * k, with b=1, k=12
act_mem_gb = (m["s"] * 1 * m["d"] * m["L"] * 12) / 1e9
total_gb = param_mem_gb + act_mem_gb
a100s = max(1, -(-int(total_gb) // 80)) # ceil division by 80
rows.append([
m["name"],
f'{N/1e9:.0f}B',
f'{param_mem_gb:.1f} GB',
f'{act_mem_gb:.1f} GB',
f'{total_gb:.1f} GB',
f'{a100s}x A100 (80GB)'
])
js.window.py_table_data = json.dumps({
"headers": ["Modelo", "Params", "Pesos+Opt+Grad", "Activaciones (b=1)", "Total", "GPUs Mín"],
"rows": rows
})
print("Estimaciones de memoria para fine-tuning completo con AdamW (precisión mixta)")
print("Activaciones asumen batch_size=1, seq_len=2048, k=12 bytes/elemento")
print()
print("Conclusión clave: incluso un modelo de 7B excede los 80GB de VRAM de una sola A100.")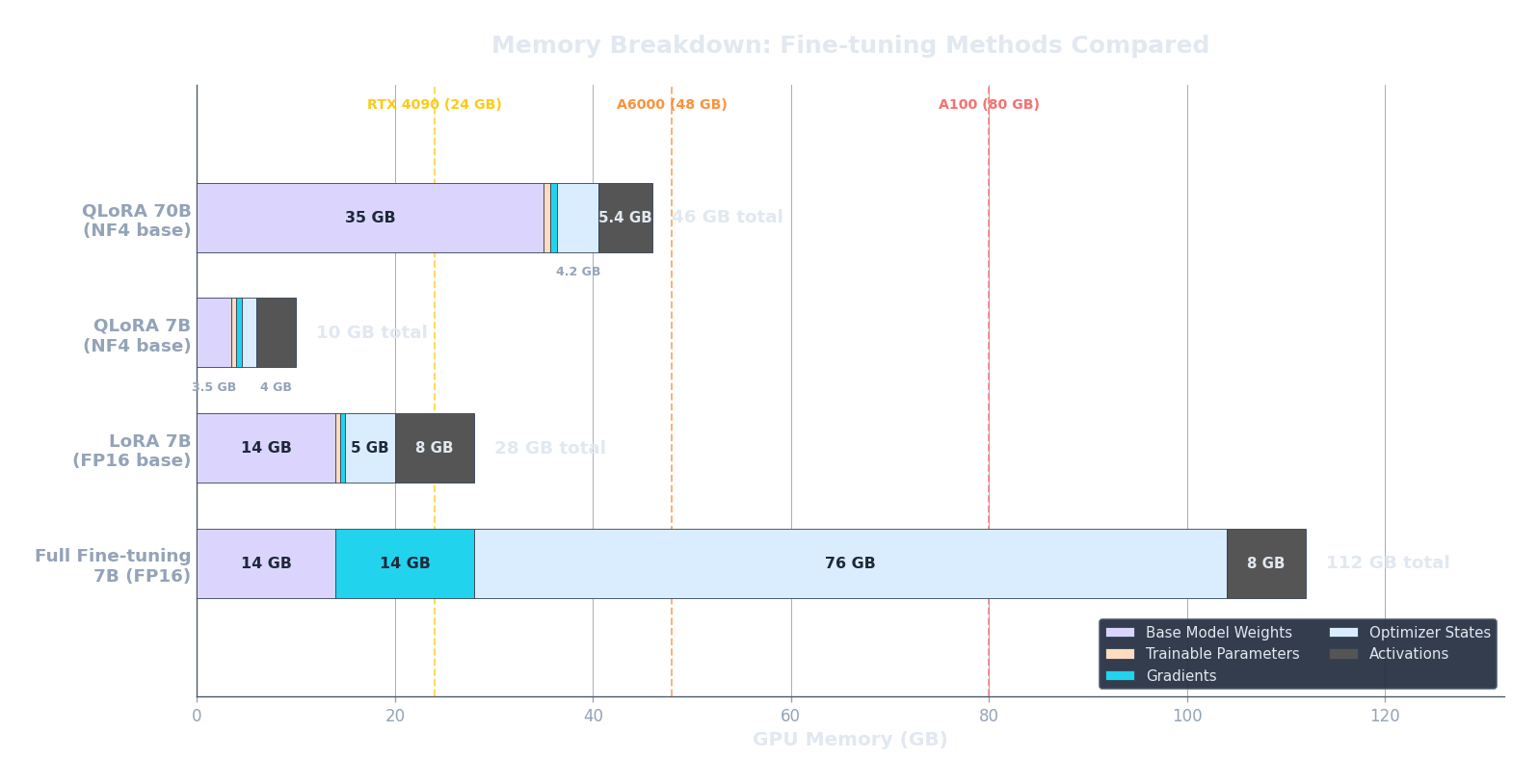
La memoria es el costo más visible del fine-tuning completo, pero no es el único. Incluso si tienes suficiente memoria GPU para meter todos los pesos, gradientes y estados del optimizador, hay un problema más sutil: actualizar cada parámetro significa que cada parámetro puede alejarse de su valor pre-entrenado. ¿Qué pasa con las capacidades generales del modelo cuando todos esos pesos se mueven?
Olvido Catastrófico
Supongamos que haces fine-tuning de un modelo de propósito general en preguntas y respuestas médicas. Se vuelve excelente en medicina — pero ahora ya no puede escribir código Python. No tocaste los datos de código, y no le pediste que olvidara. ¿Qué pasó?
Este fenómeno se llama olvido catastrófico (French, 1999) : cuando el fine-tuning en la tarea B causa que el modelo se degrade en la tarea A. Es uno de los problemas más antiguos y persistentes en la investigación de redes neuronales. El mecanismo es directo: las actualizaciones de gradiente empujan los pesos hacia la distribución de fine-tuning y lejos de todo lo demás . El modelo no actualiza selectivamente solo los parámetros responsables de la nueva tarea — los actualiza todos, y los parámetros que codificaban capacidades generales se sobrescriben en el proceso.
Geométricamente, piensa en el paisaje de pérdida como una superficie de alta dimensión con muchos valles. El pre-entrenamiento encontró un valle que funciona bien para muchas tareas simultáneamente. El fine-tuning empuja los pesos hacia un valle más estrecho que funciona brillantemente para la tarea de fine-tuning pero puede estar lejos de los valles que servían a otras tareas. Cuantos más pasos demos (y más grandes sean los pasos), más nos alejamos del mínimo de propósito general.
Hay varias estrategias prácticas para mitigar el olvido:
- Tasa de aprendizaje baja: empuja, no sobrescribas. El pre-entrenamiento típicamente usa tasas de aprendizaje alrededor de $10^{-3}$. Para fine-tuning, $10^{-5}$ a $5 \times 10^{-5}$ es estándar. Cuanto más pequeños los pasos, más cerca nos quedamos del valle pre-entrenado.
- Entrenamiento corto: 1–3 épocas es a menudo suficiente. Cada época adicional empuja los pesos más hacia la distribución de fine-tuning. Más épocas significa más olvido — hay una compensación directa entre rendimiento específico de la tarea y retención de capacidad general.
- Mezcla de datos: incluye una fracción de datos de pre-entrenamiento (o un proxy diverso) en la mezcla de fine-tuning. Esto le da al modelo un recordatorio continuo de sus capacidades generales. Muchas recetas de fine-tuning en producción mezclan 5–10% de datos generales junto con los datos de la tarea.
- Regularización: penaliza explícitamente a los pesos por alejarse demasiado de $\theta_0$. Esta es la idea detrás de Elastic Weight Consolidation (EWC) (Kirkpatrick et al., 2017) y penalidades L2 más simples.
La idea de regularización puede expresarse formalmente. En lugar de minimizar solo la pérdida de la tarea, agregamos una penalización que crece a medida que los pesos se alejan de sus valores pre-entrenados:
Aquí $\mathcal{L}_{\text{task}}$ es la pérdida de entrenamiento estándar ( entropía cruzada para modelado de lenguaje, por ejemplo). $\theta$ es el conjunto actual de pesos y $\theta_0$ es el punto de partida pre-entrenado. El término $\|\theta - \theta_0\|^2$ es la distancia L2 al cuadrado entre los pesos actuales y los originales — mide cuánto nos hemos alejado. Y $\lambda$ es un hiperparámetro que controla la fuerza de la penalización.
Verifiquemos los límites. Si $\lambda = 0$, la penalización desaparece por completo y obtenemos fine-tuning puro — los pesos son libres de moverse a donde el gradiente de pérdida de la tarea los lleve. Si $\lambda \to \infty$, la penalización domina la pérdida y los pesos efectivamente no pueden cambiar en absoluto — no hay aprendizaje porque cualquier desviación de $\theta_0$ es infinitamente penalizada. En la práctica, $\lambda$ se establece en algún punto intermedio: lo suficientemente fuerte para prevenir desviaciones salvajes, lo suficientemente débil para permitir una adaptación genuina a la tarea.
Tasa de Aprendizaje: El Hiperparámetro Más Importante
Si el fine-tuning completo se trata de mover pesos pre-entrenados hacia una nueva tarea, la tasa de aprendizaje decide qué tan lejos se mueven en cada paso. Si te equivocas pasa una de dos cosas: demasiado alta y saltas fuera de la buena región que el modelo pre-entrenado encontró (olvido catastrófico, divergencia, picos de pérdida); demasiado baja y apenas te mueves (cómputo desperdiciado, subajuste). Para fine-tuning, la tasa de aprendizaje importa más que casi cualquier otro hiperparámetro, porque el punto de partida ya codifica estructura valiosa que un tamaño de paso descuidado puede destruir.
¿Por qué la tasa de aprendizaje de fine-tuning es mucho menor que la de pre-entrenamiento? Durante el pre-entrenamiento, el modelo parte de pesos aleatorios y necesita recorrer grandes distancias en el paisaje de pérdida para encontrar una buena región. Tasas de aprendizaje de $10^{-3}$ a $10^{-4}$ son típicas. Pero en el momento del fine-tuning, ya estamos en una buena región. Solo necesitamos hacer pequeños ajustes. Una regla general: empieza 10–100x más bajo que la tasa de aprendizaje de pre-entrenamiento. Para la mayoría del fine-tuning de LLMs, esto significa $10^{-5}$ a $5 \times 10^{-5}$.
Más allá del valor pico, el calendario — cómo cambia la tasa de aprendizaje a lo largo del entrenamiento — también importa. Dos calendarios dominan el fine-tuning:
- Warmup lineal + decaimiento coseno: la tasa de aprendizaje sube linealmente desde casi cero hasta el pico durante un período de warmup (típicamente 3–10% del total de pasos), luego sigue una curva coseno de vuelta a casi cero. El warmup previene inestabilidad temprana cuando los gradientes son ruidosos, y el decaimiento coseno proporciona un recocido suave. Este es el calendario estándar para supervised fine-tuning (SFT) de LLMs.
- Constante con warmup: sube linealmente, luego se mantiene en el valor pico por el resto del entrenamiento. Más simple de implementar, menos hiperparámetros (no hay que ajustar la forma del decaimiento), y funciona sorprendentemente bien para ejecuciones cortas de fine-tuning donde el decaimiento coseno apenas tiene tiempo de activarse.
Hay un enfoque más sofisticado: tasas de aprendizaje discriminativas (Howard & Ruder, 2018) . La idea es que diferentes capas aprenden diferentes tipos de características. Las capas tempranas capturan características generales (sintaxis, morfología) que transfieren bien entre tareas y no deberían cambiar mucho. Las capas posteriores capturan características específicas de la tarea y deberían ser libres de adaptarse más agresivamente. Así que en lugar de una sola tasa de aprendizaje, asignamos una tasa menor a las capas tempranas y una mayor a las capas posteriores. En ULMFiT, la tasa de cada grupo de capas se escalaba por un factor $\xi^{-l}$ donde $l$ es la profundidad de la capa (0 = última capa) y $\xi > 1$ (típicamente 2.6), así que las capas más tempranas entrenaban a una tasa aproximadamente $\xi^{-L}$ veces menor que la última capa.
El código a continuación grafica un calendario de decaimiento coseno con warmup lineal, que es el calendario más ampliamente usado para fine-tuning de LLMs. Observa cómo la tasa de aprendizaje sube rápido durante el warmup y luego decae suavemente, pasando la mayor parte del entrenamiento en valores moderados en lugar de en el pico.
import math, json, js
total_steps = 1000
warmup_steps = 100
peak_lr = 2e-5
min_lr = 1e-6
# Compute LR at each step
steps = list(range(total_steps))
lrs_cosine = []
lrs_constant = []
for step in steps:
# -- Cosine with warmup --
if step < warmup_steps:
lr = peak_lr * (step / warmup_steps)
else:
progress = (step - warmup_steps) / (total_steps - warmup_steps)
lr = min_lr + 0.5 * (peak_lr - min_lr) * (1 + math.cos(math.pi * progress))
lrs_cosine.append(lr)
# -- Constant with warmup --
if step < warmup_steps:
lr_const = peak_lr * (step / warmup_steps)
else:
lr_const = peak_lr
lrs_constant.append(lr_const)
# Sample every 10 steps for plotting
sample = list(range(0, total_steps, 10))
x_data = [str(s) for s in sample]
plot_data = [
{
"title": "Calendarios de Tasa de Aprendizaje para Fine-tuning",
"x_label": "Paso de Entrenamiento",
"y_label": "Tasa de Aprendizaje",
"x_data": x_data,
"lines": [
{
"label": "Coseno + Warmup",
"data": [lrs_cosine[s] for s in sample],
"color": "#3b82f6"
},
{
"label": "Constante + Warmup",
"data": [lrs_constant[s] for s in sample],
"color": "#f59e0b"
}
]
}
]
js.window.py_plot_data = json.dumps(plot_data)Cuándo el Fine-tuning Completo Aún Gana
Dados los costos de memoria y los riesgos de olvido, podrías preguntarte por qué alguien sigue haciendo fine-tuning completo. La respuesta es que hay escenarios reales donde sigue siendo la mejor opción — y reconocerlos te evita aplicar métodos de eficiencia de parámetros donde no se necesitan.
- Modelos pequeños (< 1B parámetros): un modelo de 350M parámetros necesita solo $16 \times 350 \times 10^6 \approx 5.6$ GB para fine-tuning completo. Eso cabe cómodamente en una GPU de consumidor. La sobrecarga de configurar adaptadores LoRA, elegir rangos y gestionar archivos de adaptadores simplemente no vale la pena a esta escala.
- Máxima calidad: el fine-tuning completo tiene una ventaja leve pero consistente sobre los métodos de eficiencia de parámetros en muchos benchmarks. El propio artículo de LoRA (Hu et al., 2021) reporta que el fine-tuning completo iguala o supera ligeramente a LoRA, especialmente en rangos más altos. Cuando necesitas cada fracción de porcentaje de precisión — diagnóstico médico, sistemas de seguridad crítica — esa ventaja puede justificar el cómputo extra.
- Despliegue de una sola tarea: si estás desplegando un modelo para una tarea, no hay complejidad de gestión de adaptadores. Sin fusión, sin intercambio, sin composición de adaptadores. El modelo es el modelo. En producción, la simplicidad tiene valor real.
- Cuando el hardware es abundante: si tienes acceso a un clúster de 8x A100s (o mejor), la barrera de memoria deja de ser una barrera. El entrenamiento multi-GPU con ZeRO-3 (Rajbhandari et al., 2020) fragmenta el estado del optimizador, gradientes y pesos entre GPUs, así que el costo de memoria por GPU baja aproximadamente de forma lineal con el número de GPUs. En ese punto, el fine-tuning completo es igual de práctico que LoRA — y de calidad ligeramente superior.
El árbol de decisión es directo: si tu modelo cabe en memoria y puedes pagar el cómputo, el fine-tuning completo es el valor predeterminado más seguro. Es el pipeline más simple (sin hiperparámetros de adaptadores que ajustar) y da los mejores resultados. La complejidad de los métodos de eficiencia de parámetros solo se justifica cuando la memoria o el cómputo te obligan.
Pero, ¿qué pasa si no tienes 8x A100s? ¿Y si quieres hacer fine-tuning de un modelo de 70B en una sola GPU? ¿Y si necesitas servir docenas de variantes específicas de tarea desde un solo modelo base sin multiplicar tu flota de GPUs? El siguiente artículo presenta LoRA (Low-Rank Adaptation) — un método que congela los pesos pre-entrenados por completo y entrena solo pequeñas matrices de bajo rango inyectadas junto a cada capa. Reduce el costo de memoria en órdenes de magnitud mientras preserva la mayor parte de la calidad del fine-tuning completo.
Quiz
Pon a prueba tu comprensión del fine-tuning completo, sus costos y sus compensaciones.
Para un modelo con $N$ parámetros, ¿cuánta memoria GPU requiere aproximadamente el fine-tuning completo con AdamW (precisión mixta) solo para pesos, gradientes y estados del optimizador?
¿Qué es el olvido catastrófico?
¿Por qué la tasa de aprendizaje de fine-tuning es típicamente 10–100x menor que la de pre-entrenamiento?
¿En qué escenario el fine-tuning completo es claramente preferible sobre métodos de eficiencia de parámetros como LoRA?