Por qué importa la posición
Los transformers procesan todos los tokens en paralelo. A diferencia de las RNNs, que leen un token a la vez y conocen implícitamente el orden porque el token 5 se procesa después del token 4, la autoatención de un transformer calcula puntuaciones de atención entre cada par de tokens simultáneamente. Ese paralelismo es lo que hace que los transformers sean rápidos de entrenar en GPUs, pero tiene un costo: el modelo no tiene noción inherente de posición. Sin información de posición, "el gato se sentó en la alfombra" y "la alfombra se sentó en el gato" producen patrones de atención idénticos y salidas idénticas, porque el conjunto de tokens es el mismo.
El transformer original (Vaswani et al., 2017) resolvió esto con embeddings posicionales sinusoidales : vectores fijos sumados a los embeddings de tokens antes de la atención, usando funciones seno y coseno a diferentes frecuencias para dar a cada posición una firma única. Funcionan bien para secuencias cortas, pero son absolutas — cada posición recibe un vector fijo independientemente del contexto — y no extrapolan: un modelo entrenado con secuencias de longitud 512 nunca ha visto el patrón sinusoidal para la posición 513, por lo que el rendimiento se degrada en longitudes mayores.
La pregunta que impulsa este artículo es: ¿cómo codificamos la posición para que un modelo pueda manejar secuencias mucho más largas que aquellas con las que fue entrenado? Dos familias de enfoques modernos dominan:
- RoPE (Rotary Position Embedding): codifica la posición relativa rotando los vectores de query y key. Usado por LLaMA, Mistral, Qwen, Gemma y la mayoría de los LLMs modernos de pesos abiertos.
- ALiBi (Attention with Linear Biases): añade una penalización lineal simple a las puntuaciones de atención basada en la distancia entre tokens. Sin parámetros posicionales aprendidos en absoluto. Usado por BLOOM y MPT.
Construiremos desde la formulación básica de RoPE, explicaremos por qué codifica posición relativa, luego cubriremos ALiBi como una alternativa radical, y finalmente mostraremos cómo RoPE puede extenderse más allá de su longitud de entrenamiento con escalado NTK-aware y YaRN.
RoPE: Embedding de Posición Rotacional
RoPE (Su et al., 2021) codifica la posición mediante rotación de los vectores de query y key en subespacios 2D. La idea central es hermosamente geométrica: en lugar de sumar un vector de posición al embedding (lo que mezcla posición y contenido), RoPE aplica una rotación que depende de la posición. Cuando calculamos el producto punto entre un query rotado y un key rotado, los ángulos de rotación se componen de una manera que depende solo de la distancia relativa entre las dos posiciones, no de sus valores absolutos.
Así es como funciona. Dado un vector $d$-dimensional $\mathbf{x}$ en la posición $m$, se divide en $d/2$ pares consecutivos: $(x_0, x_1), (x_2, x_3), \ldots, (x_{d-2}, x_{d-1})$. Cada par $i$ se trata como un vector 2D (o equivalentemente, un número complejo $x_{2i} + ix_{2i+1}$ — ver el artículo de la fórmula de Euler para entender por qué funciona) y se rota por el ángulo $m \cdot \theta_i$:
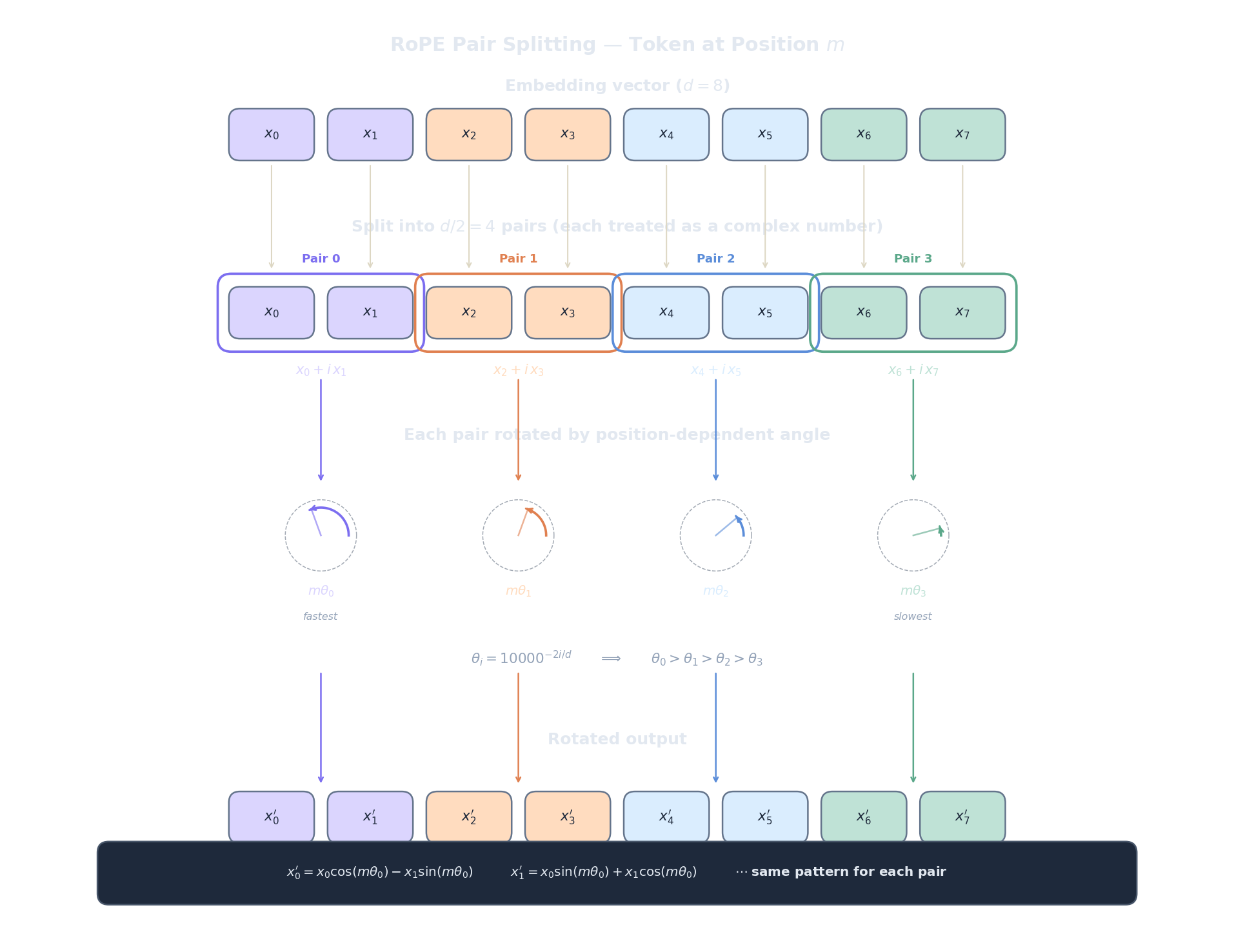
donde la frecuencia para el par de dimensiones $i$ es:
Desglosemos cada parte de esta fórmula:
- $m$ es el índice de posición (0, 1, 2, ...). Nos dice dónde se encuentra el token en la secuencia.
- $ heta_i$ es la frecuencia de rotación para el par de dimensiones $i$. Controla qué tan rápido crece el ángulo de rotación con la posición.
- $m \cdot heta_i$ es el ángulo de rotación real en radianes. La posición $m$ en el par de dimensiones $i$ se rota esta cantidad.
- The $\cos / \sin$ structure es una matriz de rotación 2D estándar aplicada al par $(x_{2i}, x_{2i+1})$. Es la misma rotación que usarías para girar un punto 2D un cierto ángulo.
Ahora el análisis de frontera para $ heta_i = 10000^{-2i/d}$. Cuando $i = 0$ (el primer par de dimensiones), $ heta_0 = 10000^0 = 1$, que es la frecuencia más alta — el ángulo de rotación crece 1 radián por posición, ciclando rápidamente. Esto codifica posición local de grano fino: tokens vecinos obtienen ángulos de rotación muy diferentes. Cuando $i = d/2 - 1$ (el último par de dimensiones), $ heta_{d/2-1} = 10000^{-1} \approx 0.0001$, una frecuencia extremadamente baja — el ángulo de rotación apenas cambia entre posiciones adyacentes. Esto codifica posición global gruesa : tokens lejanos son distinguibles, pero los vecinos lucen casi idénticos. La analogía es un sistema numérico posicional: las dimensiones de baja frecuencia son los "dígitos de orden alto" (como el lugar de las centenas), y las dimensiones de alta frecuencia son los "dígitos de orden bajo" (como el lugar de las unidades).
Ahora la propiedad crítica que hace de RoPE una codificación de posición relativa . Cuando calculamos el producto punto entre un query en la posición $m$ y un key en la posición $n$, cada par de dimensiones contribuye:
La idea clave es que esto se simplifica porque rotar por un ángulo $\alpha$ y luego tomar el producto punto con algo rotado por un ángulo $\beta$ es equivalente al producto punto sin rotar de un vector con el otro rotado por $\alpha - \beta$. En forma matricial, $R(m)^ op R(n) = R(m - n)$, donde $R(\cdot)$ es la matriz de rotación diagonal por bloques. El producto punto depende solo de la posición relativa $m - n$ , no de las posiciones absolutas $m$ y $n$ individualmente. El token 5 atendiendo al token 3 produce la misma señal posicional que el token 105 atendiendo al token 103.
Por esto RoPE se ha vuelto dominante: proporciona información de posición relativa inyectada directamente en el producto punto de atención, no requiere parámetros adicionales y se compone limpiamente con el mecanismo de atención QKV estándar. Es usado por LLaMA , Mistral , Qwen , Gemma y prácticamente todos los LLMs modernos de pesos abiertos.
El gráfico a continuación visualiza los ángulos de rotación $m \cdot heta_i$ para diferentes posiciones y pares de dimensiones. Observa cómo los primeros pares ($i$ bajo, alta frecuencia) ciclan rápidamente mientras que los últimos pares ($i$ alto, baja frecuencia) cambian muy lentamente.
import math, json, js
d = 64 # embedding dimension
n_pairs = d // 2 # 32 dimension pairs
positions = list(range(128)) # positions 0..127
# Compute theta_i for selected dimension pairs
selected_pairs = [0, 4, 12, 24, 31] # low i = high freq, high i = low freq
pair_labels = [f"pair i={i} (theta={10000**(-2*i/d):.4f})" for i in selected_pairs]
lines = []
colors = ["#ef4444", "#f59e0b", "#22c55e", "#3b82f6", "#8b5cf6"]
for idx, i in enumerate(selected_pairs):
theta_i = 10000 ** (-2 * i / d)
# Compute rotation angle mod 2*pi for visualisation
angles = [(m * theta_i) % (2 * math.pi) for m in positions]
lines.append({
"label": pair_labels[idx],
"data": [round(a, 4) for a in angles],
"color": colors[idx]
})
plot_data = [
{
"title": "RoPE Rotation Angles (mod 2pi) by Position",
"x_label": "Position m",
"y_label": "Angle (radians)",
"x_data": [str(p) for p in positions],
"lines": lines
}
]
js.window.py_plot_data = json.dumps(plot_data)
print("Low i (red) = high frequency: angle cycles rapidly with position.")
print("High i (purple) = low frequency: angle barely changes between neighbours.")
print("This multi-scale encoding lets RoPE distinguish both nearby and distant tokens.")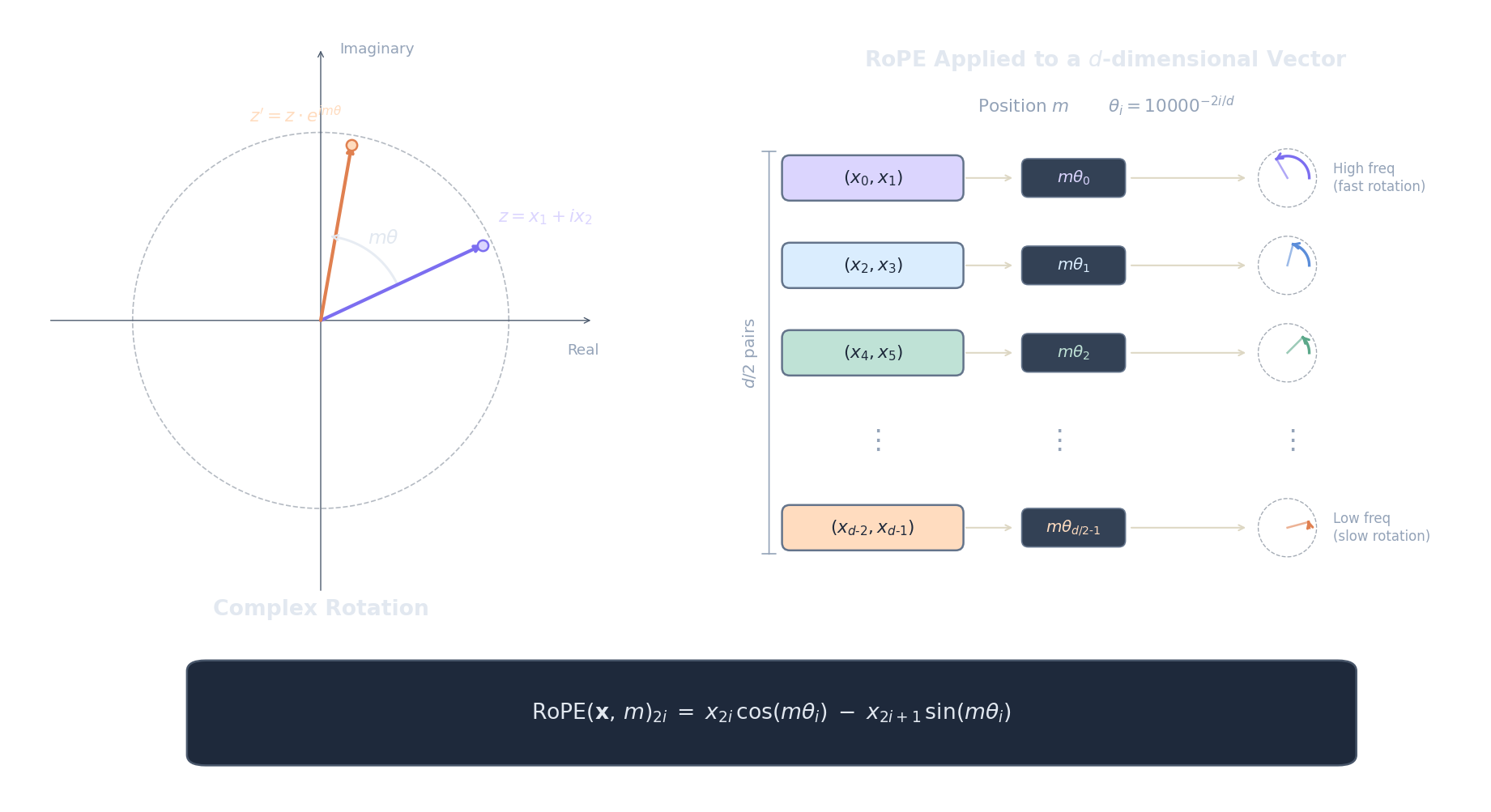
El código a continuación implementa RoPE en un vector pequeño y demuestra la propiedad de posición relativa: el producto punto entre un query rotado en la posición $m$ y un key rotado en la posición $n$ depende solo de $m - n$.
import math, json, js
def rope(x, m, d):
"""Apply RoPE rotation to vector x at position m."""
out = list(x)
for i in range(d // 2):
theta_i = 10000 ** (-2 * i / d)
angle = m * theta_i
cos_a, sin_a = math.cos(angle), math.sin(angle)
x0, x1 = x[2*i], x[2*i+1]
out[2*i] = x0 * cos_a - x1 * sin_a
out[2*i+1] = x0 * sin_a + x1 * cos_a
return out
def dot(a, b):
return sum(ai * bi for ai, bi in zip(a, b))
d = 8
# Fixed query and key vectors (content, before rotation)
q = [0.5, -0.3, 0.8, 0.1, -0.6, 0.4, 0.2, -0.7]
k = [0.3, 0.6, -0.2, 0.5, 0.7, -0.1, 0.4, 0.3]
# Compute dot products for various (m, n) pairs with same m-n
rows = []
for m, n in [(5, 3), (10, 8), (50, 48), (100, 98), (1000, 998)]:
q_rot = rope(q, m, d)
k_rot = rope(k, n, d)
dp = dot(q_rot, k_rot)
rows.append([str(m), str(n), str(m - n), f"{dp:.6f}"])
# Also show a different relative distance for contrast
for m, n in [(5, 2), (10, 7), (100, 97)]:
q_rot = rope(q, m, d)
k_rot = rope(k, n, d)
dp = dot(q_rot, k_rot)
rows.append([str(m), str(n), str(m - n), f"{dp:.6f}"])
js.window.py_table_data = json.dumps({
"headers": ["Query pos m", "Key pos n", "m - n", "Dot product"],
"rows": rows
})
print("All rows with m-n=2 have the SAME dot product regardless of absolute position.")
print("All rows with m-n=3 have a DIFFERENT (but consistent) dot product.")
print("This confirms RoPE encodes relative, not absolute, position.")ALiBi: Sin embeddings, solo sesgo
ALiBi (Press et al., 2022) toma un enfoque radicalmente diferente: eliminar todos los embeddings posicionales por completo . Sin vectores sinusoidales, sin rotaciones, sin parámetros de posición aprendidos. En su lugar, ALiBi añade un sesgo lineal simple directamente a las puntuaciones de atención que penaliza tokens distantes:
donde $m$ es una pendiente específica por cabeza . Ese es todo el método: restar una penalización proporcional a la distancia entre la posición del query $i$ y la posición del key $j$. Los tokens cercanos reciben una penalización pequeña, los tokens distantes reciben una grande, y después del softmax, esto se traduce en un sesgo de recencia: el modelo naturalmente atiende más a los tokens cercanos.
Las pendientes son fijas (no aprendidas) y forman una secuencia geométrica a través de las $H$ cabezas de atención:
para la cabeza $h = 1, 2, \ldots, H$. Diferentes cabezas obtienen diferentes pendientes, lo que significa que diferentes cabezas se especializan en diferentes rangos de atención:
- $m$ pequeño (cabezas iniciales): decaimiento suave. Un token a 100 posiciones de distancia pierde solo unos pocos puntos. Estas cabezas pueden atender ampliamente a todo el contexto.
- $m$ grande (cabezas posteriores): decaimiento pronunciado. Incluso tokens a 10 posiciones de distancia son fuertemente penalizados. Estas cabezas se enfocan en el contexto local.
Análisis de frontera: si $m = 0$, no hay sesgo posicional en absoluto — el modelo atiende uniformemente basándose solo en el contenido, como un transformer sin codificación posicional. Cuando $m o \infty$, la penalización para cualquier distancia distinta de cero se vuelve infinita, por lo que el modelo solo puede atender al token actual (posición $i = j$). La secuencia geométrica de pendientes proporciona un espectro suave entre estos extremos.
¿Por qué ALiBi extrapola tan bien? El sesgo lineal es un prior inductivo simple: "los tokens recientes tienen más probabilidad de ser relevantes." Como es aditivo a los logits de atención sin procesar (no un embedding aprendido vinculado a índices de posición específicos), no hay nada que falle en posiciones no vistas. La posición 2048 recibe una penalización de $m \cdot 2048$ relativa al token actual, que es simplemente una versión más grande de la misma función lineal que el modelo vio durante el entrenamiento. Hay cero parámetros posicionales aprendidos.
El código a continuación muestra cómo se asignan las pendientes de ALiBi a través de las cabezas, y cómo se ve la matriz de sesgo de atención para una secuencia corta.
import math, json, js
H = 8 # number of attention heads
seq_len = 6
# Compute ALiBi slopes: m_h = 2^(-8h/H) for h=1..H
slopes = [2 ** (-8 * h / H) for h in range(1, H + 1)]
rows_slopes = []
for h in range(H):
rows_slopes.append([
f"Head {h+1}",
f"{slopes[h]:.6f}",
"Broad (global)" if slopes[h] < 0.01 else "Narrow (local)" if slopes[h] > 0.1 else "Medium"
])
js.window.py_table_data = json.dumps({
"headers": ["Head", "Slope m", "Attention Range"],
"rows": rows_slopes
})
# Show bias matrix for head 1 (smallest slope) and head 8 (largest slope)
print(f"Slopes range from {slopes[0]:.6f} (head 1, broadest) to {slopes[-1]:.6f} (head {H}, narrowest)")
print(f"Head 1 penalty for distance 100: {slopes[0] * 100:.2f}")
print(f"Head {H} penalty for distance 100: {slopes[-1] * 100:.1f}")
print(f"Head 1 barely penalises distant tokens; Head {H} makes them nearly invisible after softmax.")ALiBi es usado por BLOOM (BigScience, 176B parámetros) y MPT (MosaicML). Sin embargo, a pesar de su elegancia, la mayoría de los modelos más nuevos han convergido en RoPE. Una razón es que el decaimiento lineal estricto de ALiBi puede ser demasiado agresivo para tareas que requieren dependencias de largo alcance: la atención a tokens distantes se suprime por diseño, lo que ayuda a la extrapolación pero puede perjudicar cuando el modelo genuinamente necesita información de 1000 tokens atrás.
Extendiendo RoPE: Escalado NTK-Aware y YaRN
RoPE no extrapola bien por defecto. Si un modelo fue entrenado con una longitud máxima de secuencia $L = 4096$, ¿qué pasa en la posición $m = 5000$? Los ángulos de rotación $m \cdot heta_i$ alcanzan valores que el modelo nunca vio durante el entrenamiento. Para los pares de dimensiones de alta frecuencia, los ángulos dan la vuelta completa (lo cual está bien, ya que el modelo vio todas las fases). Pero para los pares de baja frecuencia, los ángulos entran en un rango completamente nuevo, y el modelo produce patrones de atención degradados.
Varios métodos abordan esto modificando cómo se escalan las posiciones o frecuencias.
Escalado lineal (usado por Meta para Code Llama) es el enfoque más simple. Para extender desde la longitud de entrenamiento $L$ a la longitud objetivo $L'$, se dividen todas las posiciones por un factor de escala $s = L'/L$:
Esto mapea el rango extendido $[0, L']$ de vuelta a $[0, L]$, para que el modelo solo vea ángulos de rotación que encontró durante el entrenamiento. Pero tiene un costo: todas las frecuencias se comprimen por el mismo factor, y las dimensiones de alta frecuencia (que codifican posición local de grano fino) pierden resolución. Tokens que antes eran distinguibles (posiciones 10 y 11) ahora se mapean a posiciones que están solo a $1/s$ de distancia, dificultando al modelo distinguir vecinos.
Escalado NTK-aware (bloc97, 2023) adopta un enfoque más inteligente. En lugar de escalar posiciones (lo que perjudica a todas las frecuencias por igual), cambia la frecuencia base :
donde $b = 10000$ es la base original y $\alpha$ depende de la razón de extensión $L'/L$. La idea clave es que esto modifica las diferentes bandas de frecuencia de manera diferente. Recuerda la analogía del sistema numérico: las dimensiones de RoPE son como dígitos en un sistema numérico posicional. Las dimensiones de baja frecuencia son los "dígitos de orden alto" (posición gruesa: ¿en qué bloque de miles de tokens estamos?), y las dimensiones de alta frecuencia son los "dígitos de orden bajo" (posición fina: ¿qué token específico dentro de una ventana local?).
Cuando aumentamos la base, los componentes de baja frecuencia (que ya están cerca de $10000^{-1}$) se comprimen aún más — su rango se extiende para cubrir la secuencia más larga. Pero los componentes de alta frecuencia (cercanos a $10000^0 = 1$) apenas se ven afectados, preservando la capacidad del modelo para distinguir tokens adyacentes. Es como extender el rango de un sistema numérico (añadiendo más "dígitos de orden alto") sin tocar los dígitos menos significativos. Esto es mucho mejor que el escalado lineal, que también difumina los dígitos de grano fino.
YaRN (Peng et al., 2023) refina esto aún más con tres innovaciones:
- Interpolación NTK por partes: en lugar de aplicar un solo factor de escala a todas las dimensiones, YaRN las divide en tres grupos. Las dimensiones de baja frecuencia (dígitos de orden alto) se interpolan, porque necesitan cubrir un rango más amplio. Las dimensiones de alta frecuencia (dígitos de orden bajo) se mantienen sin cambios, porque ya funcionan bien para la posición local. Las dimensiones de frecuencia media obtienen una rampa suave entre los dos tratamientos.
- Corrección de temperatura de atención: extender el contexto cambia la distribución de los logits de atención (más tokens significa que el softmax se vuelve más plano). YaRN compensa con un factor de temperatura:
donde $s$ es el factor de escala. Cuando $s = 1$ (sin extensión), $t = 1$ y la atención no cambia. A medida que $s$ crece, $t$ aumenta ligeramente, agudizando el softmax para compensar el mayor número de posiciones compitiendo por masa de atención. Con extensión de $s = 4 imes$, $t \approx 1.14$; con $s = 16 imes$, $t \approx 1.28$. El crecimiento logarítmico significa que la corrección es suave y no sobrecorrige.
El resultado: YaRN puede extender la longitud de contexto de un modelo por 4-16x con solo alrededor de 400 pasos de ajuste fino (comparado con los millones de pasos en el preentrenamiento original). Muchos modelos de contexto largo de código abierto usan YaRN o variantes estrechamente relacionadas. La extensión de contexto de LLaMA 3, por ejemplo, usa una técnica de la misma familia — tratamiento diferenciado por dimensión de las frecuencias de RoPE combinado con una cantidad modesta de entrenamiento continuo.
Comparación de codificaciones de posición
La tabla a continuación resume los métodos de codificación de posición que hemos cubierto. El campo ha convergido en gran medida en RoPE más alguna forma de escalado de frecuencia para la mayoría de los LLMs de producción. ALiBi sigue siendo una alternativa interesante con cero parámetros aprendidos, pero su adopción se ha desacelerado. Los embeddings sinusoidales se consideran obsoletos para modelos solo-decodificador, aunque todavía se usan en algunas arquitecturas de codificador.
import json, js
rows = [
["Sinusoidal (Vaswani 2017)", "0", "Absolute", "Poor", "Original Transformer", "Fixed sin/cos added to embeddings"],
["Learned Absolute", "L * d", "Absolute", "None", "GPT-2, BERT", "Lookup table per position"],
["RoPE (Su 2021)", "0", "Relative (via rotation)", "Poor without scaling", "LLaMA, Mistral, Qwen, Gemma", "Rotates Q,K in 2D subspaces"],
["ALiBi (Press 2022)", "0", "Relative (via bias)", "Good (native)", "BLOOM, MPT", "Linear penalty on distance"],
["RoPE + Linear Scaling", "0", "Relative", "Moderate", "Code Llama", "Divide positions by scale factor"],
["RoPE + NTK-aware", "0", "Relative", "Good", "Various open-source", "Scale the base frequency"],
["RoPE + YaRN (Peng 2023)", "0 + temp", "Relative", "Excellent", "Many long-context models", "Per-band scaling + temperature"],
]
js.window.py_table_data = json.dumps({
"headers": ["Method", "Learned Params", "Type", "Extrapolation", "Used By", "Key Idea"],
"rows": rows
})
print("The trend is clear: the field moved from absolute to relative encodings,")
print("and from fixed methods to ones that can be extended post-training.")
print("RoPE + scaling variants dominate modern LLMs.")Un patrón se destaca: todo método exitoso codifica posición relativa (RoPE, ALiBi) o puede adaptarse para manejar posiciones más allá de la longitud de entrenamiento (las variantes de escalado). Las codificaciones absolutas (sinusoidal, aprendida) están fundamentalmente limitadas porque vinculan cada posición a una representación fija, haciendo imposible la extrapolación sin modificaciones.
Quiz
Pon a prueba tu comprensión de las codificaciones de posición para contexto largo.
¿Por qué el producto punto $ ext{RoPE}(q, m)^ op \cdot ext{RoPE}(k, n)$ depende solo de $m - n$ y no de $m$ y $n$ individualmente?
En ALiBi, ¿qué sucede cuando la pendiente específica por cabeza $m$ es muy grande?
¿Cuál es la principal ventaja del escalado NTK-aware sobre el escalado lineal simple para extender RoPE?
En RoPE, el par de dimensiones $i=0$ tiene $ heta_0 = 1$ (alta frecuencia) y el último par tiene $ heta \approx 0.0001$ (baja frecuencia). ¿Qué logra este diseño multiescala?