La Idea de la Representación Densa
El artículo anterior terminó con un problema: BM25 solo puede emparejar documentos que comparten exactamente las mismas palabras que la consulta. Busca "paro cardíaco" y no encontraremos ningún documento que diga "ataque al corazón". No importa cuán buena sea la fórmula de puntuación: cero términos compartidos significa puntuación cero.
¿Y si, en lugar de emparejar palabras, emparejáramos significados? La idea detrás de la recuperación densa es representar cada documento y consulta como un vector compacto (típicamente de 768 dimensiones) donde la proximidad geométrica captura la similitud semántica. Dos textos que significan lo mismo terminan cerca en este espacio, incluso si no comparten ninguna palabra.
La función de puntuación se convierte en un producto punto (o similitud coseno) entre estos vectores:
La mayoría de los modelos de recuperación densa normalizan sus vectores de salida a longitud unitaria ($\|\mathbf{e}_q\| = \|\mathbf{e}_d\| = 1$), lo que hace que el producto punto y la similitud coseno sean idénticos: $\mathbf{e}_q \cdot \mathbf{e}_d = \cos \theta$. Cuando decimos "similitud" a lo largo de este artículo, cualquiera de las dos métricas produce el mismo ranking.
En este espacio, "paro cardíaco" y "ataque al corazón" pueden tener vectores casi idénticos, así que la recuperación encuentra documentos sobre cualquiera de los dos. El problema de desajuste de vocabulario del artículo anterior desaparece. La contrapartida es que perdemos la búsqueda exacta por índice invertido que hacía rápidos a los métodos dispersos, y en su lugar necesitamos búsqueda aproximada de vecinos más cercanos para encontrar vectores cercanos eficientemente (cubierto en el artículo 7).
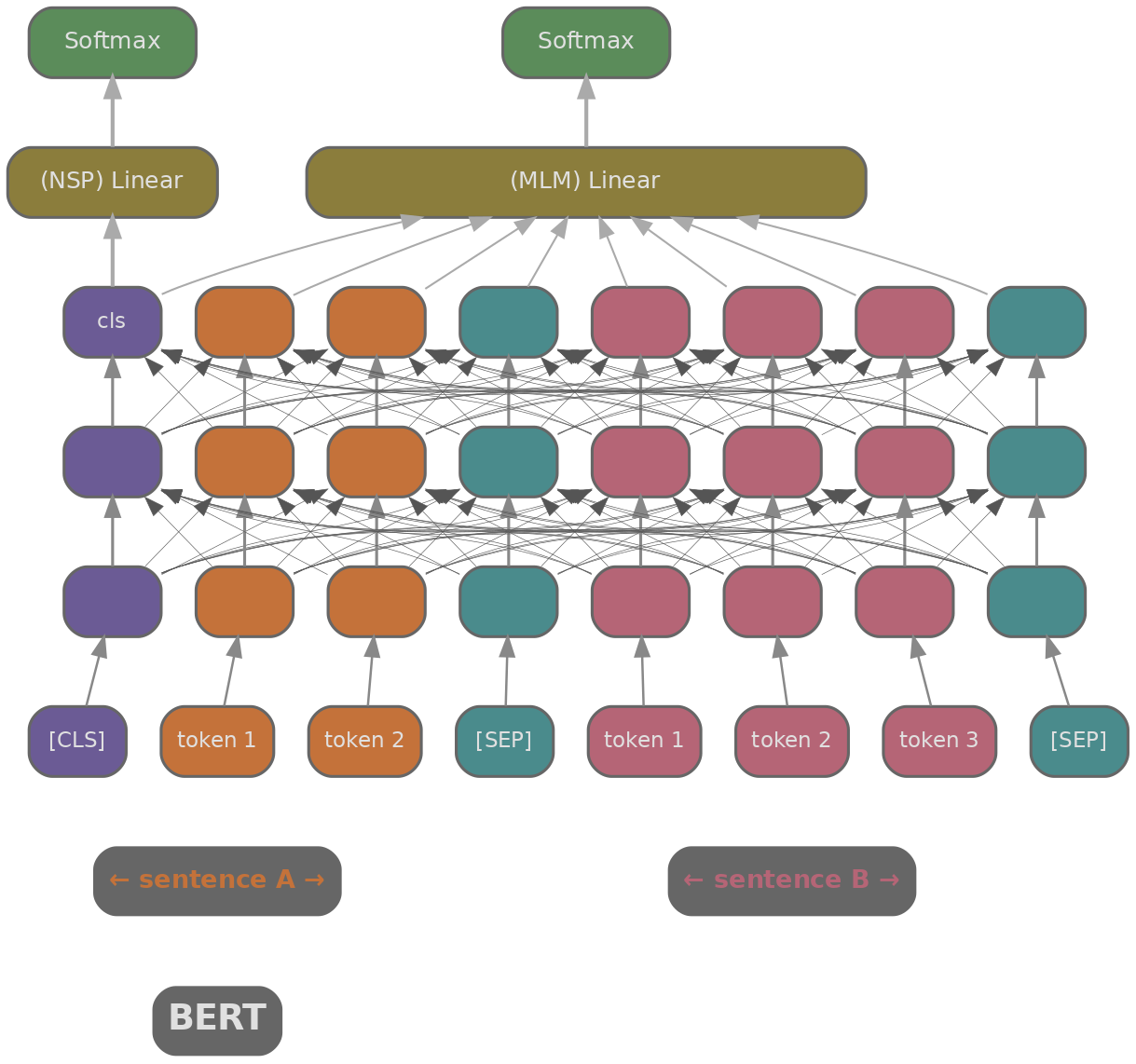
BERT: La Fundación Contextual
Necesitamos una forma de convertir texto en un vector que capture su significado. BERT (Devlin et al., 2019) (Bidirectional Encoder Representations from Transformers) fue el primer modelo en hacer esto bien. Es un encoder transformer entrenado con modelado de lenguaje enmascarado (MLM) y predicción de siguiente oración (NSP), que produce embeddings contextuales donde la representación de cada token depende del contexto completo que lo rodea.
La forma más obvia de usar BERT para recuperación es concatenar la consulta y el documento juntos: [CLS] consulta [SEP] documento [SEP], y luego usar la salida del token [CLS] para predecir la relevancia. Esto se llama cross-encoder : cada token de la consulta atiende a cada token del documento a través de todas las capas del transformer, por lo que el modelo captura interacciones detalladas entre ellos. En benchmarks como MS MARCO (Bajaj et al., 2016) , los cross-encoders logran excelentes puntuaciones de relevancia.
El problema es computacional. Puntuar una consulta contra 10 millones de documentos significa 10 millones de pasadas hacia adelante a través de BERT. A aproximadamente 2ms por pasada en una GPU, eso son alrededor de 20,000 segundos por consulta. Los cross-encoders son precisos pero demasiado lentos para recuperación de primera etapa.
SBERT: Codificando Consulta y Documento por Separado
Si el cuello de botella del cross-encoder es que consulta y documento deben procesarse juntos, la solución natural es codificarlos por separado. Sentence-BERT (Reimers & Gurevych, 2019) introdujo esta arquitectura de bi-encoder : dos modelos BERT (compartiendo pesos) cada uno produce un embedding de forma independiente, dando a la consulta su propio vector y al documento su propio vector, de modo que la recuperación se reduce a un cálculo de similitud entre ellos.
Como los embeddings de documentos no dependen de la consulta, podemos calcularlos todos offline y almacenarlos en un índice denso. En tiempo de consulta, solo ejecutamos una pasada hacia adelante (para la consulta) y luego hacemos una búsqueda vectorial rápida contra los embeddings de documentos precalculados. Puntuar una consulta contra 10 millones de documentos se convierte en una multiplicación de matrices en lugar de 10 millones de pasadas hacia adelante de BERT.
Para obtener un único vector a partir de la secuencia de embeddings de tokens de BERT, necesitamos una estrategia de pooling:
- Pooling [CLS]: usar el embedding del token [CLS] directamente. Simple, pero [CLS] fue entrenado para predicción de siguiente oración (una señal binaria gruesa), no para producir un buen resumen a nivel de oración, por lo que tiende a tener un rendimiento inferior en tareas de recuperación.
- Mean pooling: promediar todos los embeddings de tokens (excluyendo el padding): $\mathbf{e} = \frac{1}{|T|} \sum_{i \in T} \mathbf{h}_i$. Esto tiende a superar al pooling [CLS] en la mayoría de benchmarks de similitud, probablemente porque incorpora señal de cada token en lugar de depender de una sola posición.
- Max pooling: tomar el máximo elemento a elemento a través de todas las posiciones de tokens. Captura la característica más fuerte por dimensión, pero es menos común en la práctica.
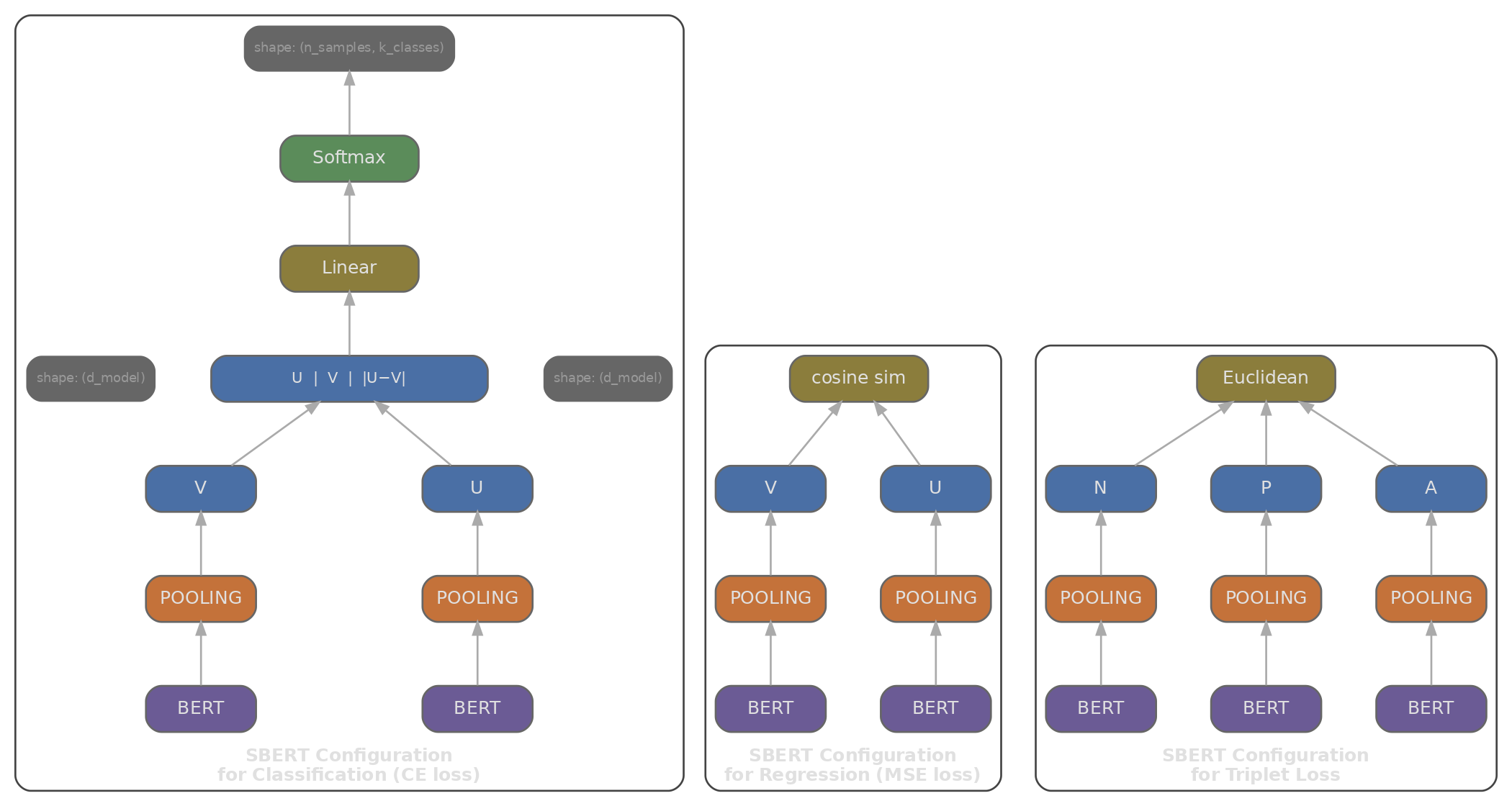
SBERT se entrena con conjuntos de datos de Inferencia de Lenguaje Natural (NLI): pares de oraciones etiquetados como implicación (acercar), contradicción (alejar) o neutral. Esto le da un buen sentido general de similitud semántica, pero no fue entrenado específicamente para recuperación.
DPR: Entrenando Bi-Encoders para Recuperación
SBERT conoce la similitud semántica, pero la recuperación es una tarea diferente. "¿Cuánto mide la Torre Eiffel?" y "La Torre Eiffel mide 330 metros" no son semánticamente similares en el sentido de NLI (una es una pregunta, la otra una afirmación), pero la segunda es exactamente lo que queremos recuperar. Dense Passage Retrieval (Karpukhin et al., 2020) (DPR) abordó esto entrenando bi-encoders de extremo a extremo con datos de preguntas y respuestas: dada una pregunta, recuperar el pasaje de Wikipedia que contiene la respuesta.
DPR usa dos encoders BERT separados: uno para consultas, otro para pasajes. Los dos encoders se ejecutan de forma independiente (dos pasadas hacia adelante separadas), por lo que las consultas y los pasajes nunca atienden entre sí. El entrenamiento usa una pérdida contrastiva llamada InfoNCE que empuja el pasaje positivo de cada pregunta más cerca en el espacio de embeddings mientras aleja los negativos:
¿De dónde vienen los negativos? Entrenamos con $B$ pares consulta-pasaje por lote. Cada consulta $q_i$ tiene un pasaje positivo $p_i^+$. Como los $B$ pasajes se codifican en el mismo lote, los $B-1$ pasajes que pertenecen a otras consultas sirven como negativos para $q_i$ (es improbable que sean relevantes para $q_i$). Esta técnica se llama in-batch negatives , y es eficiente porque un lote de $B$ pares produce $B$ ejemplos de entrenamiento con $B-1$ negativos cada uno, todos provenientes de pasadas hacia adelante que ya estábamos calculando. La matriz de similitud resultante es $B \times B$, las entradas diagonales son positivos, y la pérdida suma a lo largo de las filas. DPR también mezcla algunos negativos difíciles de BM25 por consulta para fortalecer la señal de entrenamiento.
DPR demostró que entrenar específicamente con datos de recuperación supera sustancialmente a usar SBERT (entrenado para similitud general) para recuperación de pasajes, con la precisión top-20 saltando de aproximadamente 59% a 79% en Natural Questions (Karpukhin et al., 2020, Tabla 1) . Esta brecha sugiere que el espacio de embeddings óptimo para recuperación no es el mismo que para similitud general de oraciones.
La simulación a continuación muestra cómo evoluciona la pérdida InfoNCE a medida que avanza el entrenamiento. Construimos una matriz de similitud $B \times B$ en cuatro etapas (sin entrenar, temprano, medio, convergido) y calculamos la pérdida media a lo largo de las consultas. A medida que las entradas diagonales (pares positivos) comienzan a dominar, la pérdida desciende.
import math, json
import js
# Simulate the in-batch negatives training signal
# For a batch of B queries, we compute a B x B similarity matrix
# Loss = NLL on the diagonal (positive pairs)
def softmax(logits):
m = max(logits)
exp_logits = [math.exp(x - m) for x in logits]
s = sum(exp_logits)
return [e / s for e in exp_logits]
def infonce_loss(sim_matrix):
"""For each query row, the diagonal entry is the positive."""
B = len(sim_matrix)
losses = []
for i in range(B):
row = sim_matrix[i]
probs = softmax(row)
# Loss is negative log probability of the diagonal (positive)
losses.append(-math.log(probs[i] + 1e-9))
return losses
# Simulate similarity matrices at different training stages
B = 6
# Early training: embeddings close to random, low contrast
def make_matrix(diag_boost, off_diag_noise, B):
matrix = []
for i in range(B):
row = []
for j in range(B):
if i == j:
row.append(diag_boost + (0.1 * ((i * 3 + 7) % 5 - 2)) / 10)
else:
row.append(off_diag_noise * ((i * 7 + j * 13 + 11) % 10 - 5) / 10)
matrix.append(row)
return matrix
stages = [
("Untrained", make_matrix(0.1, 0.8, B)),
("Early", make_matrix(0.5, 0.4, B)),
("Mid", make_matrix(1.2, 0.2, B)),
("Converged", make_matrix(2.5, 0.1, B)),
]
labels = [f"Query {i+1}" for i in range(B)]
stage_names = [s[0] for s in stages]
mean_losses = [sum(infonce_loss(s[1])) / B for s in stages]
plot_data = [
{
"title": "InfoNCE Loss vs Training Stage",
"x_label": "Training Stage",
"y_label": "Mean InfoNCE Loss",
"x_data": stage_names,
"lines": [
{"label": "Mean Loss", "data": [round(l, 3) for l in mean_losses], "color": "#3b82f6"},
]
}
]
js.window.py_plot_data = json.dumps(plot_data)
¿Cómo Mejoraron los Bi-Encoders Después de DPR?
Una vez establecida la arquitectura bi-encoder, la pregunta pasó del diseño del modelo al entrenamiento. La arquitectura en sí no cambió mucho; las mejoras vinieron de mejores datos, lotes más grandes, modelos base más fuertes y pipelines de entrenamiento multi-etapa.
E5 (Wang et al., 2022) (EmbEddings from bidirEctional Encoder rEpresentations) demostró que un enfoque de dos etapas funciona bien: primero preentrenar con un conjunto masivo de pares débilmente supervisados (texto-título, pregunta-respuesta, consulta-documento extraídos de Common Crawl), luego afinar con datos etiquetados de recuperación de alta calidad más pequeños. La etapa de supervisión débil expone al modelo a la distribución de consultas y documentos reales a escala; el afinamiento luego agudiza la señal con etiquetas de relevancia precisas.
GTE (Li et al., 2023) (General Text Embeddings) y BGE (Xiao et al., 2023) (BAAI General Embedding) extendieron esta receta con ventanas de contexto más largas (hasta 8192 tokens), ajuste por instrucciones y soporte multilingüe.
Un truco que usan modelos como E5 y BGE es anteponer una instrucción corta a la consulta. En lugar de codificar la consulta directamente, el modelo recibe algo como "Represent this sentence for searching relevant passages: <query>". La instrucción desplaza el embedding para favorecer recall sobre precisión, frecuentemente mejorando la recuperación sin requerir ningún cambio en el índice de documentos.
Más recientemente, modelos de lenguaje grandes se han usado como bi-encoders. E5-mistral-7B (Wang et al., 2023) usa Mistral-7B-v0.1 como modelo base con una estrategia de pooling del último token (dado que los modelos solo-decoder procesan tokens de izquierda a derecha, el último token ha atendido a todos los anteriores), produciendo embeddings de 4096 dimensiones que frecuentemente requieren cuantización o reducción de dimensionalidad para índices prácticos.
Esto crea una tensión entre calidad de representación y tamaño del índice. Un bi-encoder BERT-base produce 768 valores float32 por documento (aproximadamente 3KB), mientras que un bi-encoder LLM de 7B a 4096 dimensiones ocupa aproximadamente 16KB. Con 100 millones de documentos, esa diferencia es aproximadamente 300GB versus 1.6TB de almacenamiento de índice bruto, antes de considerar los costos de codificación.
Quiz
Pon a prueba tu comprensión de los métodos de recuperación densa.
¿Por qué no se puede usar un cross-encoder BERT como recuperador de primera etapa sobre millones de documentos?
¿Cuál es la diferencia arquitectónica clave entre un bi-encoder y un cross-encoder?
En la pérdida InfoNCE de DPR, ¿qué sirve como ejemplos negativos para una consulta dada?
El mean pooling sobre todos los embeddings de tokens tiende a superar al pooling [CLS] para recuperación de oraciones porque:
El Matryoshka Representation Learning (MRL) te permite: