El problema del chunking
Hemos cubierto cómo puntuar documentos (BM25, bi-encoders, ColBERT, rerankers) y cómo combinar puntuaciones (fusión híbrida). Pero todo esto asume que los documentos ya están en el índice, listos para buscar. ¿Cómo llegan ahí? Un sistema RAG necesita recuperar el pasaje específico que responde a una consulta, no un PDF de 50 páginas. Cada documento debe dividirse en fragmentos (chunks) antes de generar embeddings, y luego esos embeddings deben organizarse para una búsqueda rápida.
Los fragmentos pequeños (64-128 tokens) ofrecen recuperación precisa pero pueden perder contexto. Una oración sobre "la condición del paciente" puede perder contexto crítico sin el párrafo circundante. Los fragmentos grandes (512-1024 tokens) preservan el contexto pero diluyen el embedding (un fragmento de 1000 tokens que es 80% texto repetitivo podría generar un embedding similar al de muchos otros fragmentos, perjudicando la precisión).
Existen varias estrategias de chunking, que van desde simples hasta bastante sofisticadas.
- Chunking de tamaño fijo divide cada $N$ tokens con un solapamiento de $M$ tokens (por ejemplo, 512 tokens, 64 de solapamiento). Es simple, rápido y robusto, porque el solapamiento evita cortar una oración relevante exactamente en el límite de un fragmento.
- Chunking por límite de oración divide en oraciones (usando spaCy, NLTK o regex) y las agrupa en fragmentos que se mantienen bajo un límite de tokens, preservando unidades lingüísticas.
- División recursiva por caracteres intenta dividir primero por párrafos, luego por oraciones, luego por palabras (lo que mantenga los fragmentos bajo el tamaño objetivo). El divisor de texto predeterminado de LangChain usa este enfoque.
- Chunking semántico genera embeddings de cada oración, calcula la similitud coseno entre oraciones adyacentes y divide donde la similitud cae por debajo de un umbral, agrupando texto temáticamente coherente.
- Chunking basado en estructura del documento usa la estructura del documento (encabezados Markdown, etiquetas HTML, saltos de sección en PDF) para respetar los límites lógicos. Una sección titulada "Trabajo Relacionado" es un fragmento natural.
El solapamiento de fragmentos importa porque sin él, una oración que cruza el límite de un fragmento tendrá su significado cortado a la mitad. Un solapamiento del 10-15% (por ejemplo, 64 tokens en un fragmento de 512 tokens) es un valor predeterminado razonable.
HNSW: Approximate Nearest Neighbours
Una vez que los fragmentos están embebidos, necesitamos encontrar los top-$k$ vectores más similares a un vector de consulta de manera eficiente. La búsqueda exacta de vecinos más cercanos sobre $N$ vectores de dimensión $d$ requiere $O(Nd)$ operaciones por consulta. Para 10 millones de vectores de 768 dimensiones, eso son 7.68 mil millones de multiplicaciones por consulta, lo cual es demasiado lento para uso interactivo.
Hierarchical Navigable Small World (HNSW) (Malkov & Yashunin, 2018) es el algoritmo dominante de approximate nearest neighbour para recuperación densa. Construye un grafo multicapa donde cada nodo es un vector, y las capas forman una jerarquía de gruesa a fina.
- Las capas superiores contienen pocos nodos con conexiones dispersas de largo alcance, usadas para navegación gruesa que salta rápidamente a la región del espacio que contiene los vecinos más cercanos.
- Las capas inferiores contienen todos los nodos con conexiones densas y locales, usadas para búsqueda de grano fino que recorre el vecindario local para encontrar los vecinos más cercanos reales.
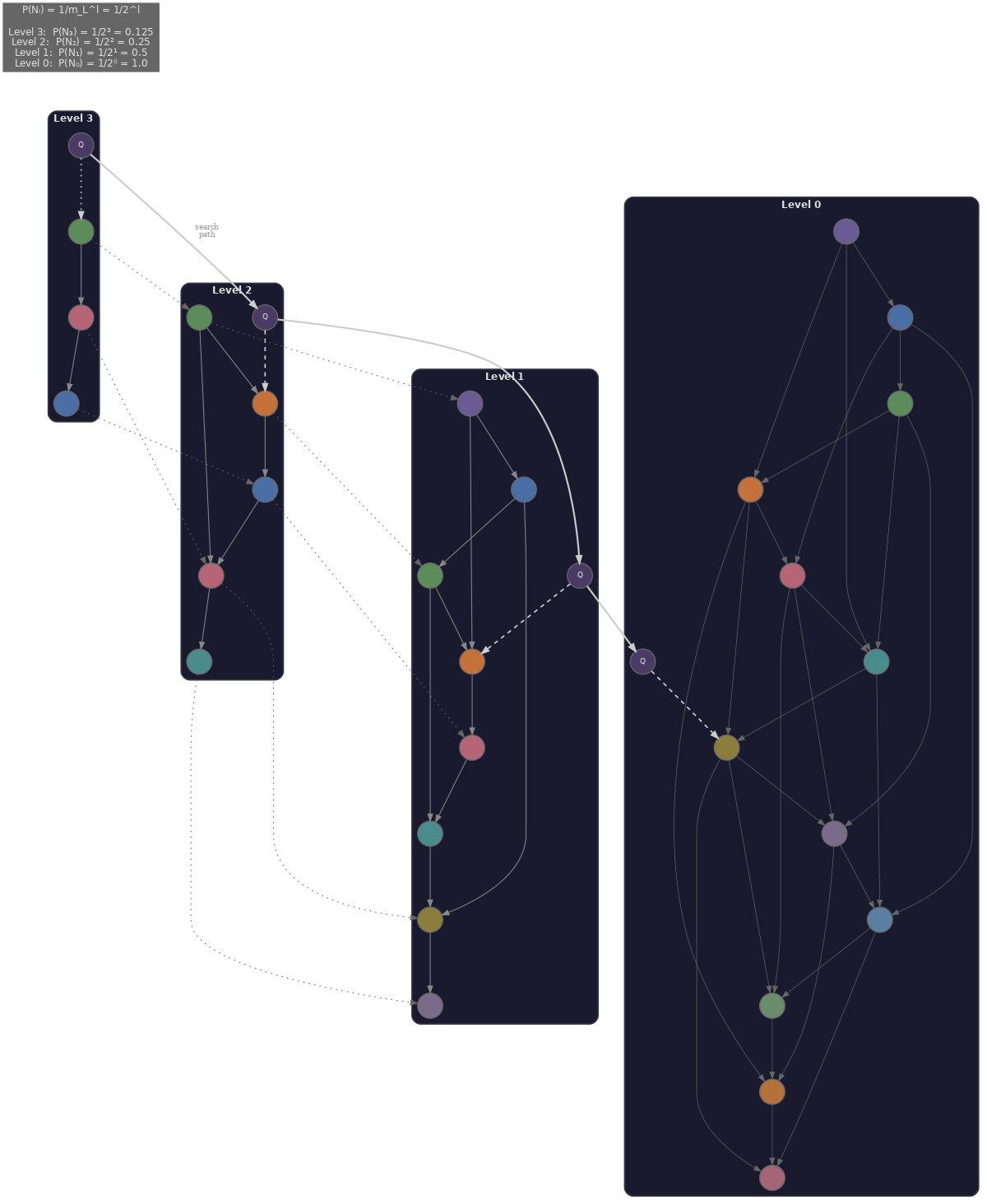
Tres hiperparámetros controlan el compromiso entre recall y velocidad.
- $M$ (conectividad) es el número de aristas por nodo por capa. Un $M$ mayor da mejor recall pero usa más memoria y ralentiza la construcción; el valor predeterminado es típicamente 16.
- $\text{efConstruction}$ es el tamaño de la lista dinámica de candidatos durante la construcción del índice. Valores más grandes producen un índice de mejor calidad a costa de una construcción más lenta; el valor predeterminado es típicamente 200.
- $\text{ef}$ (efSearch) es el tamaño de la lista de candidatos durante la búsqueda. Valores más grandes mejoran el recall pero ralentizan las consultas; el valor predeterminado es típicamente 50. A diferencia de los otros dos, podemos ajustar este por consulta sin reconstruir el índice.
La complejidad de búsqueda de HNSW es aproximadamente $O(\log N)$ por consulta (recorriendo la jerarquía), comparado con $O(N)$ para búsqueda exacta. Los benchmarks empíricos en la suite ann-benchmarks muestran que HNSW rutinariamente alcanza 95-99% de recall@10 a 10-100x la velocidad de la búsqueda exacta, dependiendo de la configuración del índice y el dataset. El compromiso fundamental es que aumentar ef da mayor recall a costa de consultas más lentas.
HNSW es el índice predeterminado en FAISS (`IndexHNSWFlat`), Weaviate y Qdrant. Una limitación es que los grafos HNSW residen completamente en memoria. Para 10 millones de vectores float32 de 768 dimensiones, solo el almacenamiento en bruto es $10^7 \times 768 \times 4 \text{ bytes} = 30.72\text{ GB}$, y las aristas del grafo añaden sobrecarga adicional. Esto hace que HNSW sea considerablemente más intensivo en memoria que los índices basados en IVF.
IVF y Product Quantisation
Inverted File Index (IVF) adopta un enfoque diferente: primero agrupa todos los vectores en $C$ centroides usando k-means (típicamente $C = 4\sqrt{N}$), luego en tiempo de consulta busca solo dentro de los $n_{\text{probe}}$ clusters más cercanos. Esto reduce el espacio de búsqueda de $N$ a aproximadamente $\frac{N \cdot n_{\text{probe}}}{C}$ vectores.
FAISS `IndexIVFFlat` es la implementación directa. Con $C=1024$ y $n_{\text{probe}}=8$, buscamos en 8/1024 = 0.8% del corpus por consulta. El compromiso es que el recall depende de si los vecinos más cercanos realmente caen dentro de los clusters explorados. IVF tiende a ser más rápido que HNSW para $N$ muy grande (porque limita la búsqueda a una fracción fija de clusters, mientras que la sobrecarga de recorrido del grafo de HNSW crece con el tamaño del corpus), pero generalmente tiene menor recall con el mismo presupuesto de velocidad.
Product Quantisation (PQ) aborda el problema de memoria. Cada vector de 768 dimensiones se divide en $M$ subvectores de dimensión $d/M = 768/M$, y cada subvector se cuantiza a una de $K'=256$ palabras código (almacenadas como un índice de 1 byte). El vector float32 original (768 x 4 = 3072 bytes) se comprime a solo $M$ bytes (una relación de compresión de 3072/$M$).
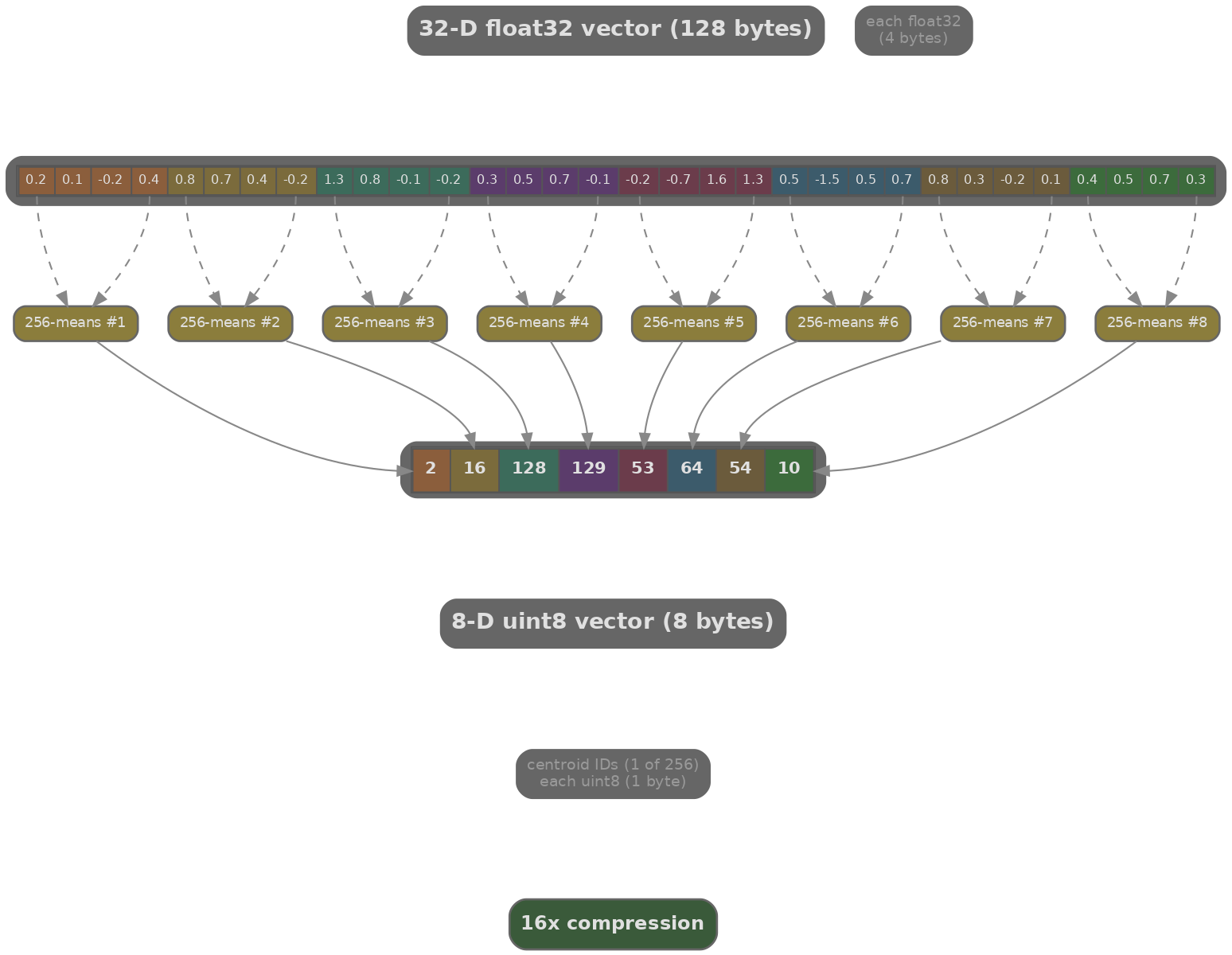
Con $M=96$, un vector de 768 dimensiones se comprime de 3072 bytes a 96 bytes (compresión 32x). El producto punto entre la consulta y un vector comprimido se aproxima como la suma de búsquedas en tablas de distancia precalculadas, una por subvector. Esto hace que PQ no solo sea eficiente en memoria sino rápido: las tablas precalculadas convierten multiplicaciones de punto flotante en búsquedas de enteros.
IVFPQ combina ambas ideas: la partición IVF limita el alcance de búsqueda, y PQ dentro de cada cluster comprime los vectores almacenados. FAISS `IndexIVFPQ` es la opción estándar de producción para corpus muy grandes (cientos de millones de vectores), donde el costo total por consulta es $n_{\text{probe}}$ exploraciones de clusters multiplicado por el número de vectores por cluster multiplicado por $M$ búsquedas PQ por vector.
La simulación a continuación ilustra cómo HNSW e IVF intercambian recall por velocidad a medida que variamos sus hiperparámetros de tiempo de búsqueda (ef para HNSW, nprobe para IVF).
import math, json
import js
# Simulate the recall vs speed trade-off for HNSW and IVF
# as a function of their search-time hyperparameters
# HNSW: increasing ef improves recall but increases latency
ef_values = [10, 20, 50, 100, 200, 500]
# Simulated: recall saturates near 1.0, latency grows linearly
hnsw_recall = [round(1 - 0.12 * math.exp(-0.012 * ef), 3) for ef in ef_values]
hnsw_latency = [round(0.5 + 0.004 * ef, 2) for ef in ef_values] # ms
# IVF: increasing nprobe improves recall but increases latency
nprobe_values = [1, 4, 8, 16, 32, 64]
ivf_recall = [round(1 - 0.35 * math.exp(-0.06 * np), 3) for np in nprobe_values]
ivf_latency = [round(0.3 + 0.15 * np, 2) for np in nprobe_values] # ms
# Common x-axis: latency in ms; plot recall vs latency
plot_data = [
{
"title": "Recall vs Query Latency: HNSW (ef) vs IVF (nprobe)",
"x_label": "Query Latency (ms)",
"y_label": "Recall@10",
"x_data": [str(l) for l in hnsw_latency],
"lines": [
{"label": "HNSW (ef)", "data": hnsw_recall, "color": "#3b82f6"},
{"label": "IVF (nprobe)", "data": ivf_recall, "color": "#f59e0b"},
]
}
]
js.window.py_plot_data = json.dumps(plot_data)
Quiz
Pon a prueba tu comprensión de las estrategias de chunking e indexación de vectores.
¿Por qué es importante el solapamiento de fragmentos en el chunking de tamaño fijo?
En HNSW, ¿qué hace aumentar el parámetro `ef` (efSearch) en tiempo de consulta?
Product Quantisation (PQ) logra la compresión mediante:
La estrategia de fragmentos padre-hijo devuelve el fragmento _______ al LLM pero indexa el fragmento _______ para la recuperación.
IVFPQ se prefiere sobre HNSW para corpus muy grandes (cientos de millones de vectores) principalmente porque: