¿Qué Se Pierde en un Solo Vector?
El artículo anterior introdujo los bi-encoders, que codifican consulta y documento por separado y comparan sus vectores únicos. Los documentos pueden precalcularse, así que la recuperación es rápida. Pero hay una compresión incómoda ocurriendo debajo: un documento de cientos de tokens se comprime en un solo vector de 768 números. Cada palabra, frase y relación entre ellas tiene que caber en ese único punto en el espacio, y el modelo tiene que producir este resumen antes de siquiera saber qué consulta se va a hacer.
Los cross-encoders evitan este problema porque cada token de la consulta atiende a cada token del documento, pero son demasiado lentos para recuperación de primera etapa. Así que la pregunta se convierte en: ¿podemos mantener el detalle por token mientras seguimos precalculando las representaciones de documentos?
Esa es la idea de interacción tardía , propuesta por primera vez en ColBERT (Khattab & Zaharia, 2020) . Codificamos consulta y documento de forma independiente (para que los documentos puedan precalcularse), pero en lugar de agrupar todo en un solo vector, mantenemos un vector por token y retrasamos la comparación hasta el momento de la puntuación.
¿Cómo Puntúa ColBERT una Consulta Contra un Documento?
ColBERT codifica una consulta en una matriz $\mathbf{Q} \in \mathbb{R}^{N_q \times d}$ (un vector de $d$ dimensiones por token de consulta) y un documento en $\mathbf{D} \in \mathbb{R}^{N_d \times d}$ (un vector por token de documento). La función de puntuación, llamada MaxSim, funciona en dos pasos: para cada token de consulta $i$, encontramos el token de documento $j$ con el que es más similar y tomamos esa similitud, luego sumamos el resultado sobre todos los tokens de consulta.
Esto es una forma suave y diferenciable de emparejamiento de términos. Un token de consulta para "cardíaco" encontrará su mejor coincidencia entre los vectores de tokens del documento, ya sea que ese token corresponda a "cardíaco", "corazón" o incluso "coronario" (si esos conceptos se superponen en el espacio de embeddings). La suma sobre tokens de consulta significa que cada parte de la consulta contribuye a la puntuación final, ponderada por qué tan bien el documento la aborda.
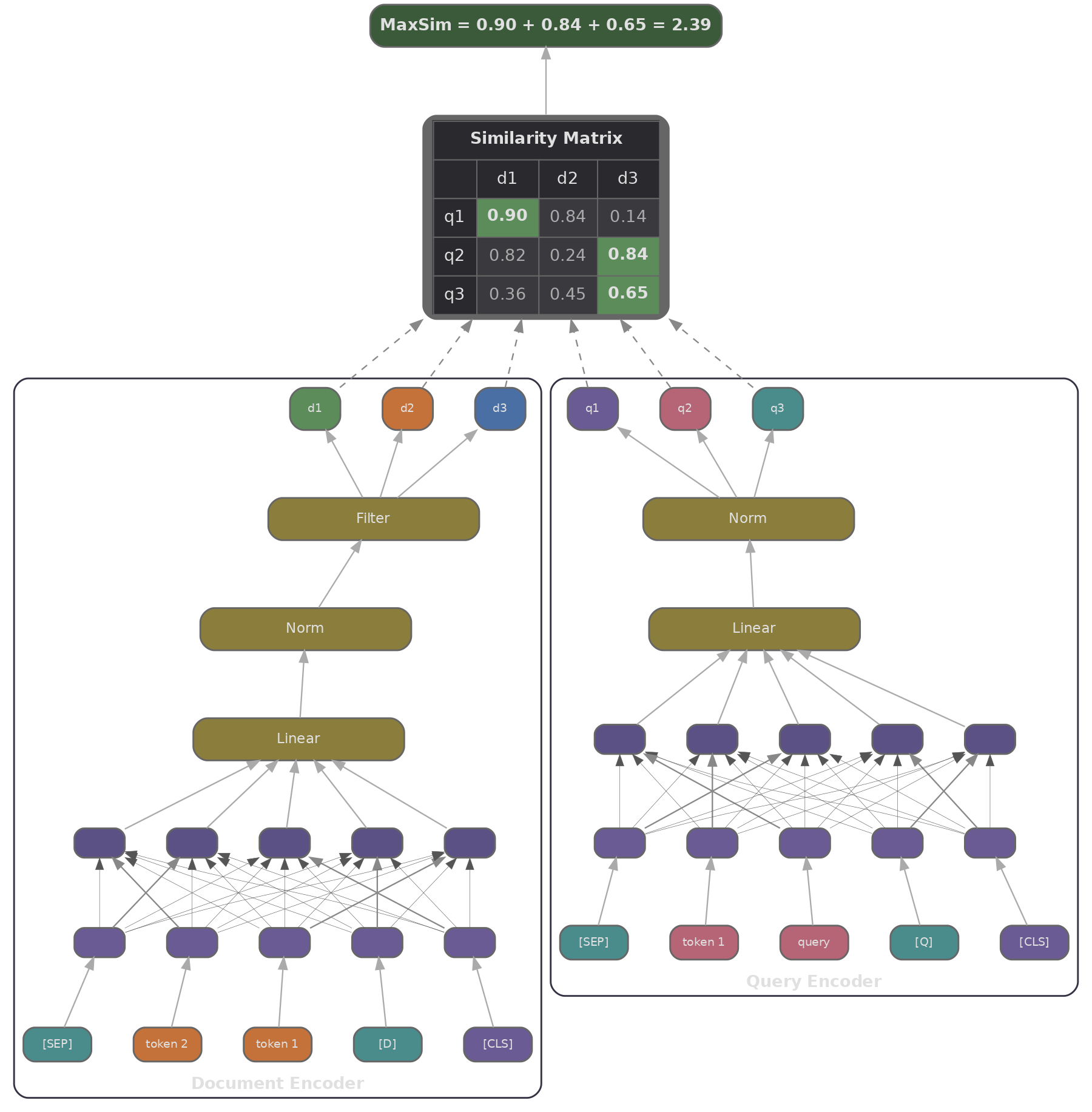
En PyTorch, podemos calcular MaxSim a lo largo de un lote de consultas y pasajes con un solo einsum seguido de un max y una suma.
import torch
# q_reps: (num_queries, num_query_tokens, dim)
# p_reps: (num_passages, num_passage_tokens, dim)
# Step 1: compute all token-to-token dot products
# token_scores[q, p, i, j] = dot(q_reps[q, i], p_reps[p, j])
token_scores = torch.einsum('qin,pjn->qipj', q_reps, p_reps)
# Step 2: for each query token i, find the max over passage tokens j
# max_scores[q, p, i] = max_j token_scores[q, p, i, j]
max_scores, _ = token_scores.max(dim=-1)
# Step 3: sum over query tokens
# scores[q, p] = sum_i max_scores[q, p, i]
scores = max_scores.sum(dim=-1)
La notación einsum
'qin,pjn->qipj'
dice: para cada combinación de consulta $q$, pasaje $p$, token de consulta $i$ y token de pasaje $j$, calcular el producto punto sobre la dimensión de embedding $n$. El resultado es un tensor 4D con una puntuación de similitud por combinación consulta-pasaje-token-token; el max y la suma subsiguientes colapsan esas dos últimas dimensiones en una sola puntuación por par consulta-pasaje.
Comparado con la puntuación de bi-encoders, el costo computacional de ColBERT en tiempo de consulta es mayor porque MaxSim tiene que comparar $N_q \times N_d$ pares de tokens por par consulta-pasaje. Pero sigue siendo mucho más barato que un cross-encoder, ya que las matrices de tokens de documentos $\mathbf{D}$ están precalculadas y en caché.
¿Cómo Maneja ColBERT el Aumento de Índice de 30x?
ColBERT usa un objetivo de entrenamiento contrastivo similar a DPR, pero la pérdida opera sobre puntuaciones MaxSim en lugar de productos punto de vectores agrupados. Durante el entrenamiento, las representaciones de consulta se rellenan con tokens [MASK] hasta una longitud fija, y estos embeddings [MASK] aprenden a actuar como espacios de expansión (términos de consulta suaves que el modelo llena con contexto relevante). El efecto es similar a la expansión de vocabulario de SPLADE del artículo 2, pero ocurre a nivel de embedding de tokens en lugar del nivel de vocabulario.
El aumento de índice de 30x es un problema real de despliegue. La solución práctica es un enfoque de dos etapas: la búsqueda aproximada de vecinos más cercanos sobre vectores de tokens individuales primero identifica pasajes candidatos (usando un índice FAISS sobre todos los vectores de tokens de documentos), y luego calculamos puntuaciones MaxSim exactas solo para esos candidatos.
ColBERTv2 (Santhanam et al., 2021) abordó el tamaño del índice directamente introduciendo compresión residual, que cuantiza los vectores de tokens de documentos a códigos de 2 bits y reduce el tamaño del índice de 4 a 8 veces con mínima pérdida de calidad. PLAID (Santhanam et al., 2022) fue más allá con generación de candidatos basada en centroides: todos los vectores de tokens de documentos se agrupan en $k$ centroides, y en tiempo de consulta los centroides más cercanos de cada token de consulta determinan qué documentos se puntúan. Según el artículo de PLAID, esto reduce el cómputo de MaxSim de 50 a 100 veces mientras retiene la calidad de recuperación top-10.
¿Puede un Solo Modelo Producir las Tres Señales de Recuperación?
A este punto del track, hemos visto tres enfoques de recuperación: disperso (BM25/SPLADE), denso (bi-encoders) e interacción tardía (ColBERT). Cada uno tiene fortalezas que los otros carecen. La recuperación dispersa es precisa con palabras clave raras pero pierde paráfrasis; la recuperación densa maneja bien la sinonimia pero puede perder términos exactos; la interacción tardía ofrece la mejor calidad pero al mayor costo. Una pregunta natural es si un solo modelo puede producir las tres señales a la vez.
BGE-M3 (Chen et al., 2024) hace exactamente esto. Es un backbone encoder con tres cabezales de salida: un embedding denso (estilo bi-encoder), un vector de pesos léxicos dispersos (estilo SPLADE) y representaciones multi-vector para interacción tardía (estilo ColBERT). Cada cabezal llena una brecha diferente.
- El cabezal denso captura similitud semántica, manejando bien la paráfrasis y la sinonimia.
- El cabezal disperso hace emparejamiento exacto de palabras clave, proporcionando alta precisión para términos raros y jerga técnica.
- El cabezal multi-vector realiza emparejamiento fino a nivel de token con la mayor calidad, pero también el mayor costo.
En producción, podemos usar la recuperación densa como una primera etapa rápida, la recuperación dispersa como señal complementaria fusionada mediante Reciprocal Rank Fusion (cubierta en el artículo 5), y la puntuación multi-vector como reranker sobre los candidatos principales. Dado que las tres señales provienen del mismo modelo, sus representaciones son consistentes entre sí, evitando el desajuste de distribución que surge al mezclar modelos separados.
El entrenamiento de BGE-M3 tiene tres etapas, como se describe en Chen et al. (2024) : preentrenamiento débilmente supervisado con 1.2 mil millones de pares de datos web multilingües, afinamiento con datos de recuperación etiquetados con los tres cabezales de pérdida simultáneamente, y autodestilación de conocimiento. En el paso de destilación, el ensamble de las tres puntuaciones sirve como etiqueta suave de profesor para cada cabezal individual. La puntuación del ensamble tiende a ser más precisa que cualquier cabezal individual, por lo que destilarla de vuelta a cada cabezal incentiva a las tres representaciones a mantenerse mutuamente consistentes.
El siguiente gráfico ilustra (con datos simulados) cómo estas señales se complementan entre sí a través de diferentes tipos de consulta, y cómo combinarlas en una puntuación híbrida tiende a superar a cualquier señal individual.
import math, json
import js
# Simulate the complementary strengths of dense vs sparse vs multi-vector retrieval
# For a set of query types, show the relative recall@10
query_types = ["Semantic paraphrase", "Exact keyword", "Multi-hop reasoning", "Rare technical term", "Long question"]
# Simulated recall@10 values (0-100) for each retrieval type
dense_recall = [92, 58, 75, 45, 83]
sparse_recall = [54, 94, 60, 91, 49]
multivec_recall = [88, 85, 87, 83, 90]
hybrid_recall = [95, 96, 91, 93, 93]
plot_data = [
{
"title": "Retrieval Signal Complementarity (Simulated Recall@10)",
"x_label": "Query Type",
"y_label": "Recall@10 (%)",
"x_data": query_types,
"lines": [
{"label": "Dense", "data": dense_recall, "color": "#3b82f6"},
{"label": "Sparse", "data": sparse_recall, "color": "#f59e0b"},
{"label": "Multi-vector","data": multivec_recall, "color": "#a855f7"},
{"label": "Hybrid", "data": hybrid_recall, "color": "#10b981"},
]
}
]
js.window.py_plot_data = json.dumps(plot_data)
Quiz
Pon a prueba tu comprensión de la interacción tardía y la recuperación multi-vector.
En la puntuación MaxSim de ColBERT, ¿qué calcula la operación max?
¿Por qué el índice de ColBERT es aproximadamente 30 veces más grande que un índice de bi-encoder?
El einsum `'qin,pjn->qipj'` en la puntuación de ColBERT calcula:
BGE-M3 produce tres señales de recuperación desde un solo modelo. ¿Cuál señal es más adecuada para emparejamiento exacto de palabras clave técnicas?
En ColBERT, ¿qué aprenden a hacer los tokens [MASK] añadidos durante la aumentación de consulta?