Where Does Information Get Lost in a Sequence Model?
Recurrent neural networks process sequences one step at a time. At each timestep $t$, the hidden state $h_t$ is a function of the current input $x_t$ and the previous hidden state $h_{t-1}$:
This means that every piece of information about earlier tokens has to pass through a chain of hidden states before it can influence processing at later positions. If a sentence is 50 tokens long, information from the first token must survive 49 successive transformations before the model produces its final output. Each transformation compresses, blends, and overwrites, so by the time we reach the end, early information has often been diluted or lost entirely. This is sometimes called the sequential bottleneck , and it's a structural limitation (not a training problem).
LSTMs (Hochreiter & Schmidhuber, 1997) and GRUs (Cho et al., 2014) alleviate this with gating mechanisms that let information bypass the recurrence through a cell state or update gate. In practice, these gates help significantly with moderate-length sequences (tens of tokens), but they don't eliminate the core problem. Information still flows through a single path, step by step, and empirically LSTMs tend to struggle once sequences exceed a few hundred tokens (Khandelwal et al., 2018) . There's no shortcut that lets position 1 talk directly to position 200.
Why Did Seq2Seq Make the Problem Worse?
The sequential bottleneck becomes especially painful in sequence-to-sequence (seq2seq) models, introduced by Sutskever et al. (2014) for tasks like machine translation. A seq2seq model has two components: an encoder RNN that reads the source sentence and a decoder RNN that generates the target sentence. The encoder processes the entire input sequence and produces a final hidden state, which becomes the initial hidden state for the decoder. This single vector is the context vector (the only information the decoder has about the source).
Consider what this means for a 40-word English sentence being translated into French. The encoder compresses all 40 words (their meanings, their syntactic roles, their order) into one fixed-length vector (typically 256 or 512 dimensions). The decoder must then reconstruct the entire French sentence from that single point in vector space. For short sentences, this works surprisingly well. For longer ones, performance degrades sharply because the context vector simply doesn't have enough capacity to faithfully represent everything.
Cho et al. (2014) demonstrated this degradation directly, showing that BLEU (Papineni et al., 2002) scores for an encoder-decoder RNN dropped rapidly as source sentence length increased beyond about 20 tokens. The model wasn't failing because it lacked parameters or training data; it was failing because the architecture forced all information through a single bottleneck vector.
We can write the bottleneck formally. If $h_1^{\text{enc}}, h_2^{\text{enc}}, \ldots, h_T^{\text{enc}}$ are the encoder hidden states for a source sentence of $T$ tokens, the vanilla seq2seq model sets:
Every decoder timestep conditions on $c$ and nothing else from the source side. The information from $h_1^{\text{enc}}$ (the first word) had to survive $T-1$ recurrence steps to reach $h_T^{\text{enc}}$, and now it has to serve the entire decoding process. The problem is twofold: compression loss (too much information packed into too few dimensions) and recency bias (later tokens dominate the hidden state because they've been through fewer transformations).
How Does Bahdanau Attention Break the Bottleneck?
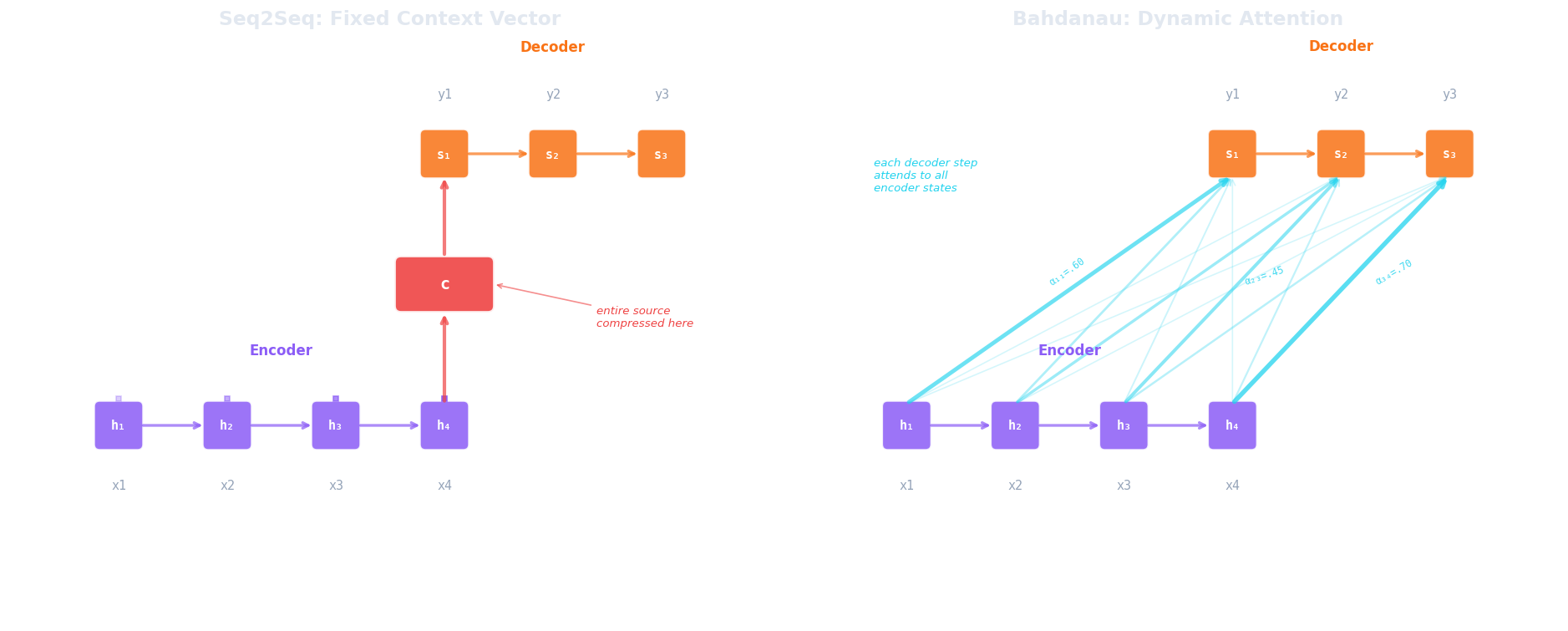
The breakthrough came from Bahdanau, Cho & Bengio (2014) , who proposed a simple but powerful change: instead of compressing the entire source into one vector, let the decoder look back at all encoder hidden states at every decoding step, and learn which ones to focus on. The context vector is no longer fixed; it's recomputed at each decoder timestep as a weighted combination of encoder states.
At each decoder step $i$, the model computes an alignment score $e_{ij}$ between the current decoder state $s_{i-1}$ and each encoder hidden state $h_j^{\text{enc}}$, then normalises these scores into attention weights $\alpha_{ij}$ with a softmax:
where $a$ is a small learned alignment network (typically a single hidden layer with $\tanh$ activation). The context vector $c_i$ for decoder step $i$ is then the weighted sum of all encoder hidden states:
Let's walk through why this solves the problem. When $\alpha_{i3}$ is large and the rest are small, $c_i$ is approximately $h_3^{\text{enc}}$ (the decoder is looking directly at the third source token). No compression through a chain of recurrence steps, no loss of early information. The decoder can attend to position 1 when generating the first target word and position 40 when generating the last, each time pulling information directly from the relevant encoder state.
Consider the edge cases. If all $\alpha_{ij}$ are equal ($\frac{1}{T}$ each), the context vector is a simple average of all encoder states, which is roughly what the fixed context vector was doing (summarising everything equally). If exactly one $\alpha_{ij} = 1$ and the rest are 0, the decoder is performing a hard lookup, reading a single encoder position. In practice, the learned weights fall somewhere between these extremes, softly selecting a few relevant positions while ignoring the rest.
The results were immediate and striking. On English-to-French translation, the attention model reversed the length-dependent degradation that had plagued seq2seq: BLEU scores remained stable even as sentence length grew, because the decoder was no longer bottlenecked through a single vector. The attention weights also turned out to be interpretable — when translating a word, the model learned to attend to the corresponding source word (or words), producing soft alignment matrices that closely resembled the hard word alignments used in traditional statistical machine translation.
But Bahdanau attention has a limitation that's easy to overlook. The encoder is still an RNN. Each $h_j^{\text{enc}}$ is computed sequentially, so building the encoder representations takes $O(T)$ serial steps. The attention mechanism lets the decoder access any encoder position directly, but the encoder itself still compresses information step by step. Similarly, the decoder is still autoregressive, and each decoder state depends on the previous one. Attention solved the information access problem (the decoder can see everything) but not the computation problem (we still can't parallelise the sequential processing). That limitation would drive the next step: what if we removed the RNN entirely and built a model from attention alone?
From Attention-on-RNNs to Attention-Is-All-You-Need
After Bahdanau's paper, attention became a standard add-on to sequence models. Luong et al. (2015) simplified the alignment function (using a dot product instead of a learned network), and attention was quickly adopted in speech recognition, image captioning, and summarisation. But in every case, attention was layered on top of an underlying RNN. The recurrence remained.
This matters for two practical reasons. First, RNNs are inherently sequential: we cannot compute $h_t$ until $h_{t-1}$ is done, which means we can't parallelise across timesteps during training. Modern GPUs are massively parallel processors, but an RNN forces them to process tokens one at a time, wasting most of their compute capacity. Second, even with attention, the RNN's hidden state still serves as the primary representation at each position, and that representation is built through the same recurrence that causes the long-range difficulties we discussed earlier.
The question that Vaswani et al. (2017) asked was radical: what if we throw away the RNN and use only attention? Instead of building representations through recurrence, every position attends to every other position directly, in parallel. The input is processed in one shot (all positions simultaneously), with attention as the sole mechanism for positions to exchange information. This is the Transformer architecture.
Removing the recurrence solves both problems at once. Without the sequential dependency between hidden states, every position can be computed in parallel during training, which makes transformers dramatically faster on GPU hardware. And because every position can attend directly to every other position (without passing through intermediate hidden states), long-range dependencies no longer require information to survive a chain of transformations. Position 1 and position 200 are connected through a single attention operation.
The next article unpacks exactly how this attention mechanism works. We'll look at the query-key-value framework that makes self-attention possible, walk through the scaled dot-product formula, and see why a seemingly simple mathematical operation (project, dot product, softmax, weighted sum) is powerful enough to replace recurrence entirely.
Quiz
Test your understanding of the motivation behind attention mechanisms.
What is the core problem with vanilla seq2seq encoder-decoder models?
How does Bahdanau attention solve the information bottleneck?
What limitation of Bahdanau attention did the Transformer architecture address?
If all attention weights α_ij are equal (1/T each), what does the context vector approximate?