What Was the Original Transformer Actually Built For?
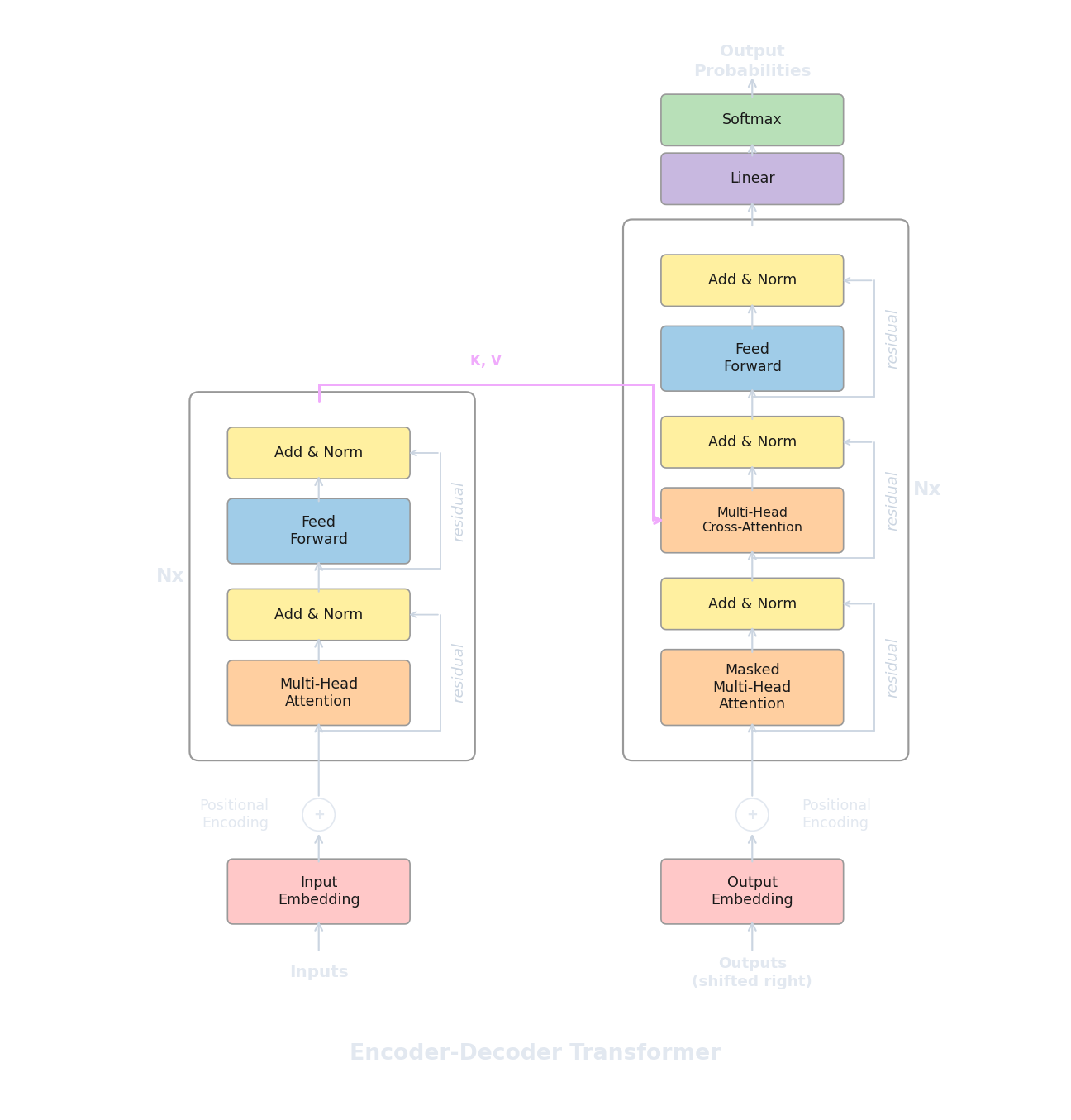
We have now seen encoders (bidirectional, good at understanding) and decoders (causal, good at generating). But the architecture from "Attention Is All You Need" (Vaswani et al., 2017) was neither an encoder alone nor a decoder alone. It was both, connected together, designed for a specific task: machine translation . Given a sentence in one language, produce the corresponding sentence in another. The original model translated English to German and English to French, and it set new state-of-the-art results on both tasks.
Translation is a natural fit for a two-part architecture because the input and output are fundamentally different sequences. The source sentence ("The cat sat on the mat") has its own structure, length, and word order, while the target sentence ("Le chat s'est assis sur le tapis") has a different structure, a different length, and different word order. An encoder can process the entire source sentence bidirectionally, building rich contextual representations of every source token. A decoder can then generate the target sentence one token at a time, but at each step it needs to "look back" at the source to decide what to translate next. This looking-back mechanism is called cross-attention , and it is the key component that distinguishes encoder-decoder models from the pure encoder and pure decoder architectures we have seen so far.
The full pipeline works as follows. The source sentence passes through all $N$ encoder layers, producing a sequence of contextual vectors (one per source token). Then the decoder generates the target sentence token by token. At each decoder layer, the decoder first applies causal self-attention over the target tokens generated so far (exactly like the standalone decoder from article 7), and then applies cross-attention where it attends to the encoder's output. The decoder repeats this process layer by layer, and the final layer's output at the current position is used to predict the next target token.
How Does Cross-Attention Differ from Self-Attention?
In every attention mechanism we have seen so far, Q, K, and V all come from the same sequence. When an encoder layer computes self-attention, the input tokens produce their own queries, keys, and values, and each token attends to other tokens in the same sequence. The same is true in the decoder's causal self-attention: the target tokens attend to each other (with a mask preventing future positions).
Cross-attention changes this in a specific way: Q comes from the decoder (the target tokens currently being generated), but K and V come from the encoder (the source sentence representations). Each decoder position generates a query that asks "which parts of the source sentence are relevant to what I'm about to generate?", and the encoder's keys and values provide the answers. The attention weights tell us how much each source token contributes to the current decoder position, and the weighted combination of encoder values becomes the cross-attention output.
Mathematically, cross-attention uses the same scaled dot-product formula as self-attention:
If the decoder has generated $m$ target tokens so far and the encoder processed $n$ source tokens, then $Q_{\text{dec}}$ is an $m \times d_k$ matrix, $K_{\text{enc}}$ and $V_{\text{enc}}$ are both $n \times d_k$ matrices, and the attention weight matrix is $m \times n$. Each row of this matrix is a probability distribution over the source positions, telling the decoder how to weight the source tokens when generating the current target token. No causal mask is needed in cross-attention because the decoder should be able to attend to any source position regardless of where it is in the generation process (the source sentence is fully available from the start).
The following code shows a complete encoder-decoder layer, with both the causal self-attention and the cross-attention components clearly separated.
import torch
import torch.nn as nn
class DecoderLayerWithCrossAttn(nn.Module):
def __init__(self, d_model=512, n_heads=8, d_ff=2048, dropout=0.1):
super().__init__()
# 1) Causal self-attention (decoder attends to itself)
self.self_attn = nn.MultiheadAttention(d_model, n_heads, batch_first=True)
self.norm1 = nn.LayerNorm(d_model)
# 2) Cross-attention (decoder attends to encoder output)
self.cross_attn = nn.MultiheadAttention(d_model, n_heads, batch_first=True)
self.norm2 = nn.LayerNorm(d_model)
# 3) Feed-forward network
self.ff = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.ReLU(),
nn.Linear(d_ff, d_model),
)
self.norm3 = nn.LayerNorm(d_model)
self.drop = nn.Dropout(dropout)
def forward(self, x, encoder_output, causal_mask=None):
# Step 1: Causal self-attention over target tokens
attn_out, _ = self.self_attn(x, x, x, attn_mask=causal_mask)
x = self.norm1(x + self.drop(attn_out))
# Step 2: Cross-attention — Q from decoder, K and V from encoder
cross_out, cross_weights = self.cross_attn(
query=x, # Q comes from the decoder
key=encoder_output, # K comes from the encoder
value=encoder_output # V comes from the encoder
)
x = self.norm2(x + self.drop(cross_out))
# Step 3: Feed-forward
ff_out = self.ff(x)
x = self.norm3(x + self.drop(ff_out))
return x, cross_weights # cross_weights: (batch, m, n)
# Shape check
d_model = 512
layer = DecoderLayerWithCrossAttn(d_model=d_model)
encoder_out = torch.randn(2, 10, d_model) # 10 source tokens
decoder_in = torch.randn(2, 7, d_model) # 7 target tokens so far
out, weights = layer(decoder_in, encoder_out)
print(f"Decoder output: {out.shape}") # [2, 7, 512]
print(f"Cross-attn weights: {weights.shape}") # [2, 7, 10] — each target attends to 10 source tokensThe cross-attention weights matrix (shape $m \times n$, or 7 target tokens by 10 source tokens in our example) is particularly informative for translation. If we visualise it, we often see a rough diagonal pattern where early target tokens attend to early source tokens and late target tokens attend to late source tokens, with deviations where word order differs between languages. Researchers have used these attention maps to study how the model learns to align source and target words, essentially rediscovering alignment patterns that earlier statistical machine translation systems had to learn through separate alignment models.
Which Models Use This Architecture?
Beyond the original transformer, two encoder-decoder models became especially influential. T5 (Text-to-Text Transfer Transformer) (Raffel et al., 2019) reframed every NLP task as a text-to-text problem: classification becomes "input: 'sentence' -> output: 'positive'", summarisation becomes "input: 'article' -> output: 'summary'", and translation becomes "input: 'translate English to French: sentence' -> output: 'la phrase'". By unifying all tasks into the same format, T5 could use a single encoder-decoder architecture for everything, and the researchers conducted a massive empirical study comparing different pre-training objectives, model sizes, and dataset compositions.
BART (Lewis et al., 2019) took a different approach to pre-training. Instead of masking individual tokens (like BERT's MLM), BART corrupts the input with a variety of noise functions (token masking, token deletion, sentence permutation, text infilling where a span of tokens is replaced by a single [MASK] token) and trains the decoder to reconstruct the original text. This denoising autoencoder setup is well suited for generation tasks like summarisation and dialogue, because the decoder has to learn to produce coherent, well-formed text from corrupted input.
Both T5 and BART showed that encoder-decoder models could be competitive across understanding and generation tasks simultaneously. The encoder handles the input comprehension (reading the article to summarise, understanding the question to answer), and the decoder handles the output generation (producing the summary, generating the answer). This flexibility came with a cost: the architecture has roughly twice the parameters of a comparable encoder-only or decoder-only model, because it maintains two separate stacks of transformer layers plus the cross-attention projections in every decoder layer.
Why Did the Field Move to Decoder-Only?
Despite the elegance of the encoder-decoder design, the field has largely converged on decoder-only architectures for general-purpose language models. GPT-3 (Brown et al., 2020) was the turning point: a 175B-parameter decoder-only model that could perform translation, summarisation, question answering, and dozens of other tasks without any fine-tuning at all, just by conditioning on a natural-language prompt. If a single decoder-only model can do everything that previously required separate architectures, the argument for maintaining a more complex two-part architecture weakens considerably.
Several practical factors drove this shift. The most obvious is scaling simplicity . A decoder-only model has one stack of layers, one set of attention parameters, and one forward pass during training. There is no encoder-decoder synchronisation to manage, no cross-attention projections to add, and no decisions about how to split the parameter budget between encoder and decoder. When scaling to hundreds of billions of parameters, this simplicity reduces engineering complexity and makes training infrastructure more straightforward.
Decoder-only models are also more data-efficient in how they use their training corpus. Because every position predicts the next token, every position produces a gradient signal. In an encoder-decoder model trained with denoising objectives, only the decoder positions (the output side) contribute to the loss, while the encoder processes the input without directly producing a training signal. When pre-training on trillions of tokens, extracting a gradient from every single token position matters.
Finally, decoder-only models handle input and output as a single unified sequence . The prompt and the generation are part of the same token stream with no separate encoder pass. This means the model naturally handles tasks where the boundary between input and output is fluid (multi-turn conversation, for instance, where each response becomes part of the context for the next turn). Encoder-decoder models require explicit decisions about what goes into the encoder versus the decoder, which becomes awkward for open-ended dialogue.
This does not mean encoder-decoder models are obsolete. For tasks with a clear input-output separation (translation, summarisation, speech-to-text), encoder-decoder architectures still offer advantages because the encoder can process the full input bidirectionally while the decoder generates the output. Whisper (Radford et al., 2022) uses an encoder-decoder architecture for speech recognition, where the encoder processes audio features and the decoder generates text. The mBART family (Liu et al., 2020) remains widely used for multilingual translation. Specialised applications where the input and output modalities differ tend to benefit from having dedicated components for each side.
The broader lesson is architectural. When we had limited compute and data, having the right inductive bias (bidirectional encoding for input, causal decoding for output, cross-attention to connect them) gave a meaningful advantage. As compute and data scaled by orders of magnitude, the simplest architecture that could be trained efficiently won out, even if it lacks the structural elegance of the encoder-decoder. We can summarise the three architectures and their characteristics in a compact comparison.
- An encoder-only model like BERT uses bidirectional attention, excels at understanding tasks, cannot generate text natively, and typically ranges from 110M to 340M parameters.
- A decoder-only model like GPT uses causal attention, generates text autoregressively, handles both understanding and generation via prompting, and scales to hundreds of billions of parameters.
- An encoder-decoder model like T5 or BART pairs a bidirectional encoder with a causal decoder connected by cross-attention. This is natural for tasks with distinct input and output, though it requires roughly 2x the parameters of a single-stack model at the same layer count.
Quiz
Test your understanding of the encoder-decoder architecture and the shift to decoder-only models.
In cross-attention, where do the Q, K, and V matrices come from?
Why is no causal mask needed in cross-attention?
What is a key practical advantage of decoder-only architectures over encoder-decoder for scaling?
How does T5 unify different NLP tasks into a single architecture?