¿Para qué fue construido originalmente el Transformer?
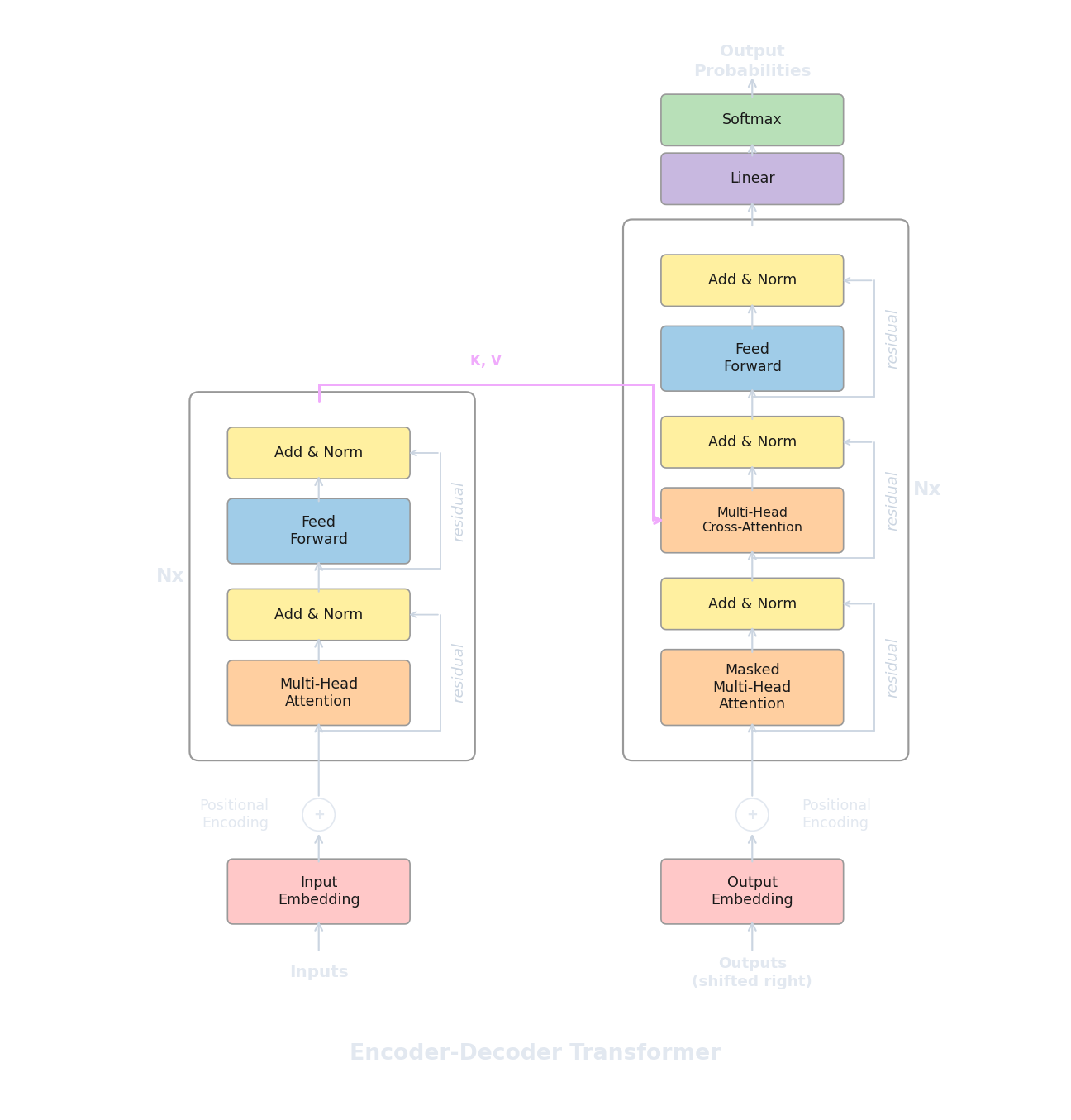
Ya hemos visto encoders (bidireccionales, buenos para comprender) y decoders (causales, buenos para generar). Pero la arquitectura de "Attention Is All You Need" (Vaswani et al., 2017) no era ni un encoder solo ni un decoder solo. Eran ambos, conectados juntos, diseñados para una tarea específica: traducción automática . Dada una oración en un idioma, producir la oración correspondiente en otro. El modelo original traducía de inglés a alemán y de inglés a francés, y estableció nuevos resultados estado del arte en ambas tareas.
La traducción es un ajuste natural para una arquitectura de dos partes porque la entrada y la salida son secuencias fundamentalmente diferentes. La oración fuente ("The cat sat on the mat") tiene su propia estructura, longitud y orden de palabras, mientras que la oración objetivo ("Le chat s'est assis sur le tapis") tiene una estructura diferente, una longitud diferente y un orden de palabras diferente. Un encoder puede procesar toda la oración fuente bidireccionalmente, construyendo representaciones contextuales ricas de cada token fuente. Un decoder puede entonces generar la oración objetivo un token a la vez, pero en cada paso necesita "mirar hacia atrás" a la fuente para decidir qué traducir a continuación. Este mecanismo de mirar hacia atrás se llama cross-attention , y es el componente clave que distingue los modelos encoder-decoder de las arquitecturas puras de encoder y decoder que hemos visto hasta ahora.
El pipeline completo funciona de la siguiente manera. La oración fuente pasa por todas las $N$ capas del encoder, produciendo una secuencia de vectores contextuales (uno por token fuente). Luego el decoder genera la oración objetivo token por token. En cada capa del decoder, el decoder primero aplica causal self-attention sobre los tokens objetivo generados hasta el momento (exactamente como el decoder independiente del artículo 7), y luego aplica cross-attention donde atiende a la salida del encoder. El decoder repite este proceso capa por capa, y la salida de la capa final en la posición actual se usa para predecir el siguiente token objetivo.
¿En qué se diferencia la cross-attention de la self-attention?
En cada mecanismo de atención que hemos visto hasta ahora, Q, K y V provienen todos de la misma secuencia. Cuando una capa del encoder calcula self-attention, los tokens de entrada producen sus propias queries, keys y values, y cada token atiende a otros tokens en la misma secuencia. Lo mismo ocurre en la causal self-attention del decoder: los tokens objetivo se atienden entre sí (con una máscara que previene posiciones futuras).
La cross-attention cambia esto de una manera específica: Q proviene del decoder (los tokens objetivo que se están generando actualmente), pero K y V provienen del encoder (las representaciones de la oración fuente). Cada posición del decoder genera una query que pregunta "¿qué partes de la oración fuente son relevantes para lo que estoy a punto de generar?", y las keys y values del encoder proporcionan las respuestas. Los pesos de atención nos dicen cuánto contribuye cada token fuente a la posición actual del decoder, y la combinación ponderada de los values del encoder se convierte en la salida de cross-attention.
Matemáticamente, la cross-attention usa la misma fórmula de producto punto escalado que la self-attention:
Si el decoder ha generado $m$ tokens objetivo hasta ahora y el encoder procesó $n$ tokens fuente, entonces $Q_{\text{dec}}$ es una matriz de $m \times d_k$, $K_{\text{enc}}$ y $V_{\text{enc}}$ son ambas matrices de $n \times d_k$, y la matriz de pesos de atención es $m \times n$. Cada fila de esta matriz es una distribución de probabilidad sobre las posiciones fuente, indicando al decoder cómo ponderar los tokens fuente al generar el token objetivo actual. No se necesita máscara causal en la cross-attention porque el decoder debería poder atender a cualquier posición fuente independientemente de dónde se encuentre en el proceso de generación (la oración fuente está completamente disponible desde el principio).
El siguiente código muestra una capa encoder-decoder completa, con los componentes de causal self-attention y cross-attention claramente separados.
import torch
import torch.nn as nn
class DecoderLayerWithCrossAttn(nn.Module):
def __init__(self, d_model=512, n_heads=8, d_ff=2048, dropout=0.1):
super().__init__()
# 1) Causal self-attention (decoder attends to itself)
self.self_attn = nn.MultiheadAttention(d_model, n_heads, batch_first=True)
self.norm1 = nn.LayerNorm(d_model)
# 2) Cross-attention (decoder attends to encoder output)
self.cross_attn = nn.MultiheadAttention(d_model, n_heads, batch_first=True)
self.norm2 = nn.LayerNorm(d_model)
# 3) Feed-forward network
self.ff = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.ReLU(),
nn.Linear(d_ff, d_model),
)
self.norm3 = nn.LayerNorm(d_model)
self.drop = nn.Dropout(dropout)
def forward(self, x, encoder_output, causal_mask=None):
# Step 1: Causal self-attention over target tokens
attn_out, _ = self.self_attn(x, x, x, attn_mask=causal_mask)
x = self.norm1(x + self.drop(attn_out))
# Step 2: Cross-attention — Q from decoder, K and V from encoder
cross_out, cross_weights = self.cross_attn(
query=x, # Q comes from the decoder
key=encoder_output, # K comes from the encoder
value=encoder_output # V comes from the encoder
)
x = self.norm2(x + self.drop(cross_out))
# Step 3: Feed-forward
ff_out = self.ff(x)
x = self.norm3(x + self.drop(ff_out))
return x, cross_weights # cross_weights: (batch, m, n)
# Shape check
d_model = 512
layer = DecoderLayerWithCrossAttn(d_model=d_model)
encoder_out = torch.randn(2, 10, d_model) # 10 source tokens
decoder_in = torch.randn(2, 7, d_model) # 7 target tokens so far
out, weights = layer(decoder_in, encoder_out)
print(f"Decoder output: {out.shape}") # [2, 7, 512]
print(f"Cross-attn weights: {weights.shape}") # [2, 7, 10] — each target attends to 10 source tokensLa matriz de pesos de cross-attention (forma $m \times n$, o 7 tokens objetivo por 10 tokens fuente en nuestro ejemplo) es particularmente informativa para la traducción. Si la visualizamos, a menudo vemos un patrón diagonal aproximado donde los tokens objetivo tempranos atienden a los tokens fuente tempranos y los tokens objetivo tardíos atienden a los tokens fuente tardíos, con desviaciones donde el orden de las palabras difiere entre idiomas. Los investigadores han usado estos mapas de atención para estudiar cómo el modelo aprende a alinear palabras fuente y objetivo, esencialmente redescubriendo patrones de alineamiento que los sistemas anteriores de traducción automática estadística tenían que aprender a través de modelos de alineamiento separados.
¿Qué modelos usan esta arquitectura?
Más allá del transformer original, dos modelos encoder-decoder se volvieron especialmente influyentes. T5 (Text-to-Text Transfer Transformer) (Raffel et al., 2019) reformuló cada tarea de NLP como un problema texto-a-texto: la clasificación se convierte en "input: 'sentence' -> output: 'positive'", el resumen se convierte en "input: 'article' -> output: 'summary'", y la traducción se convierte en "input: 'translate English to French: sentence' -> output: 'la phrase'". Al unificar todas las tareas en el mismo formato, T5 pudo usar una sola arquitectura encoder-decoder para todo, y los investigadores realizaron un estudio empírico masivo comparando diferentes objetivos de pre-entrenamiento, tamaños de modelo y composiciones de datasets.
BART (Lewis et al., 2019) tomó un enfoque diferente para el pre-entrenamiento. En lugar de enmascarar tokens individuales (como el MLM de BERT), BART corrompe la entrada con una variedad de funciones de ruido (enmascaramiento de tokens, eliminación de tokens, permutación de oraciones, relleno de texto donde un tramo de tokens se reemplaza por un solo token [MASK]) y entrena al decoder para reconstruir el texto original. Esta configuración de autoencoder de eliminación de ruido es adecuada para tareas de generación como resumen y diálogo, porque el decoder tiene que aprender a producir texto coherente y bien formado a partir de entrada corrupta.
Tanto T5 como BART mostraron que los modelos encoder-decoder podían ser competitivos en tareas de comprensión y generación simultáneamente. El encoder maneja la comprensión de la entrada (leer el artículo a resumir, entender la pregunta a responder), y el decoder maneja la generación de la salida (producir el resumen, generar la respuesta). Esta flexibilidad vino con un costo: la arquitectura tiene aproximadamente el doble de parámetros que un modelo comparable solo-encoder o solo-decoder, porque mantiene dos pilas separadas de capas transformer más las proyecciones de cross-attention en cada capa del decoder.
¿Por qué el campo se movió hacia decoder-only?
A pesar de la elegancia del diseño encoder-decoder, el campo ha convergido en gran medida hacia arquitecturas decoder-only para modelos de lenguaje de propósito general. GPT-3 (Brown et al., 2020) fue el punto de inflexión: un modelo decoder-only de 175B parámetros que podía realizar traducción, resumen, respuesta a preguntas y docenas de otras tareas sin ningún fine-tuning en absoluto, solo condicionando con un prompt en lenguaje natural. Si un solo modelo decoder-only puede hacer todo lo que anteriormente requería arquitecturas separadas, el argumento para mantener una arquitectura de dos partes más compleja se debilita considerablemente.
Varios factores prácticos impulsaron este cambio. El más obvio es la simplicidad de escalado . Un modelo decoder-only tiene una pila de capas, un conjunto de parámetros de atención y un paso forward durante el entrenamiento. No hay sincronización encoder-decoder que gestionar, no hay proyecciones de cross-attention que agregar, y no hay decisiones sobre cómo dividir el presupuesto de parámetros entre encoder y decoder. Cuando se escala a cientos de miles de millones de parámetros, esta simplicidad reduce la complejidad de ingeniería y hace que la infraestructura de entrenamiento sea más directa.
Los modelos decoder-only también son más eficientes en datos en cómo usan su corpus de entrenamiento. Debido a que cada posición predice el siguiente token, cada posición produce una señal de gradiente. En un modelo encoder-decoder entrenado con objetivos de eliminación de ruido, solo las posiciones del decoder (el lado de salida) contribuyen a la pérdida, mientras que el encoder procesa la entrada sin producir directamente una señal de entrenamiento. Cuando se pre-entrena con billones de tokens, extraer un gradiente de cada posición de token individual importa.
Finalmente, los modelos decoder-only manejan entrada y salida como una única secuencia unificada . El prompt y la generación son parte del mismo flujo de tokens sin un paso de encoder separado. Esto significa que el modelo maneja naturalmente tareas donde la frontera entre entrada y salida es fluida (conversación multi-turno, por ejemplo, donde cada respuesta se convierte en parte del contexto para el siguiente turno). Los modelos encoder-decoder requieren decisiones explícitas sobre qué va al encoder versus al decoder, lo que se vuelve incómodo para el diálogo abierto.
Esto no significa que los modelos encoder-decoder estén obsoletos. Para tareas con una separación clara entre entrada y salida (traducción, resumen, voz-a-texto), las arquitecturas encoder-decoder aún ofrecen ventajas porque el encoder puede procesar toda la entrada bidireccionalmente mientras el decoder genera la salida. Whisper (Radford et al., 2022) usa una arquitectura encoder-decoder para reconocimiento de voz, donde el encoder procesa características de audio y el decoder genera texto. La familia mBART (Liu et al., 2020) sigue siendo ampliamente utilizada para traducción multilingüe. Las aplicaciones especializadas donde las modalidades de entrada y salida difieren tienden a beneficiarse de tener componentes dedicados para cada lado.
La lección más amplia es arquitectónica. Cuando teníamos cómputo y datos limitados, tener el sesgo inductivo correcto (codificación bidireccional para la entrada, decodificación causal para la salida, cross-attention para conectarlos) daba una ventaja significativa. A medida que el cómputo y los datos escalaron en órdenes de magnitud, la arquitectura más simple que podía entrenarse eficientemente ganó, aunque carezca de la elegancia estructural del encoder-decoder. Podemos resumir las tres arquitecturas y sus características en una comparación compacta.
- Un modelo solo-encoder como BERT usa atención bidireccional, sobresale en tareas de comprensión, no puede generar texto nativamente y típicamente va de 110M a 340M parámetros.
- Un modelo solo-decoder como GPT usa atención causal, genera texto autoregressivamente, maneja tanto comprensión como generación mediante prompting, y escala a cientos de miles de millones de parámetros.
- Un modelo encoder-decoder como T5 o BART empareja un encoder bidireccional con un decoder causal conectado por cross-attention. Esto es natural para tareas con entrada y salida distintas, aunque requiere aproximadamente 2x los parámetros de un modelo de pila única con el mismo número de capas.
Quiz
Pon a prueba tu comprensión de la arquitectura encoder-decoder y el cambio hacia modelos decoder-only.
En la cross-attention, ¿de dónde provienen las matrices Q, K y V?
¿Por qué no se necesita máscara causal en la cross-attention?
¿Cuál es una ventaja práctica clave de las arquitecturas decoder-only sobre encoder-decoder para el escalado?
¿Cómo unifica T5 diferentes tareas de NLP en una sola arquitectura?