¿Dónde Se Pierde la Información en un Modelo de Secuencias?
Las redes neuronales recurrentes procesan secuencias un paso a la vez. En cada paso temporal $t$, el estado oculto $h_t$ es una función de la entrada actual $x_t$ y del estado oculto anterior $h_{t-1}$:
Esto significa que toda la información sobre tokens anteriores debe pasar a través de una cadena de estados ocultos antes de poder influir en el procesamiento en posiciones posteriores. Si una oración tiene 50 tokens, la información del primer token debe sobrevivir 49 transformaciones sucesivas antes de que el modelo produzca su salida final. Cada transformación comprime, mezcla y sobreescribe, de modo que al llegar al final, la información temprana a menudo se ha diluido o perdido por completo. Esto a veces se denomina el cuello de botella secuencial , y es una limitación estructural (no un problema de entrenamiento).
Los LSTMs (Hochreiter & Schmidhuber, 1997) y los GRUs (Cho et al., 2014) alivian esto con mecanismos de compuertas que permiten que la información omita la recurrencia a través de un estado de celda o compuerta de actualización. En la práctica, estas compuertas ayudan significativamente con secuencias de longitud moderada (decenas de tokens), pero no eliminan el problema central. La información aún fluye por un camino único, paso a paso, y empíricamente los LSTMs tienden a tener dificultades cuando las secuencias superan unos pocos cientos de tokens (Khandelwal et al., 2018) . No hay un atajo que permita a la posición 1 comunicarse directamente con la posición 200.
¿Por Qué Seq2Seq Empeoró el Problema?
El cuello de botella secuencial se vuelve especialmente problemático en los modelos sequence-to-sequence (seq2seq), introducidos por Sutskever et al. (2014) para tareas como la traducción automática. Un modelo seq2seq tiene dos componentes: un RNN encoder que lee la oración fuente y un RNN decoder que genera la oración objetivo. El encoder procesa toda la secuencia de entrada y produce un estado oculto final, que se convierte en el estado oculto inicial del decoder. Este único vector es el vector de contexto (la única información que el decoder tiene sobre la fuente).
Considera lo que esto implica para una oración en inglés de 40 palabras que se traduce al francés. El encoder comprime las 40 palabras (sus significados, sus roles sintácticos, su orden) en un único vector de longitud fija (típicamente de 256 o 512 dimensiones). El decoder debe entonces reconstruir toda la oración en francés a partir de ese único punto en el espacio vectorial. Para oraciones cortas, esto funciona sorprendentemente bien. Para oraciones más largas, el rendimiento se degrada bruscamente porque el vector de contexto simplemente no tiene capacidad suficiente para representar fielmente todo.
Cho et al. (2014) demostraron esta degradación directamente, mostrando que los puntajes BLEU (Papineni et al., 2002) de un RNN encoder-decoder caían rápidamente a medida que la longitud de la oración fuente superaba aproximadamente 20 tokens. El modelo no fallaba por falta de parámetros o datos de entrenamiento; fallaba porque la arquitectura forzaba toda la información a pasar por un único vector cuello de botella.
Podemos expresar el cuello de botella formalmente. Si $h_1^{\text{enc}}, h_2^{\text{enc}}, \ldots, h_T^{\text{enc}}$ son los estados ocultos del encoder para una oración fuente de $T$ tokens, el modelo seq2seq básico establece:
Cada paso temporal del decoder se condiciona en $c$ y en nada más del lado fuente. La información de $h_1^{\text{enc}}$ (la primera palabra) tuvo que sobrevivir $T-1$ pasos de recurrencia para llegar a $h_T^{\text{enc}}$, y ahora debe servir a todo el proceso de decodificación. El problema es doble: pérdida por compresión (demasiada información empaquetada en muy pocas dimensiones) y sesgo de recencia (los tokens posteriores dominan el estado oculto porque han pasado por menos transformaciones).
¿Cómo Rompe el Cuello de Botella la Atención de Bahdanau?
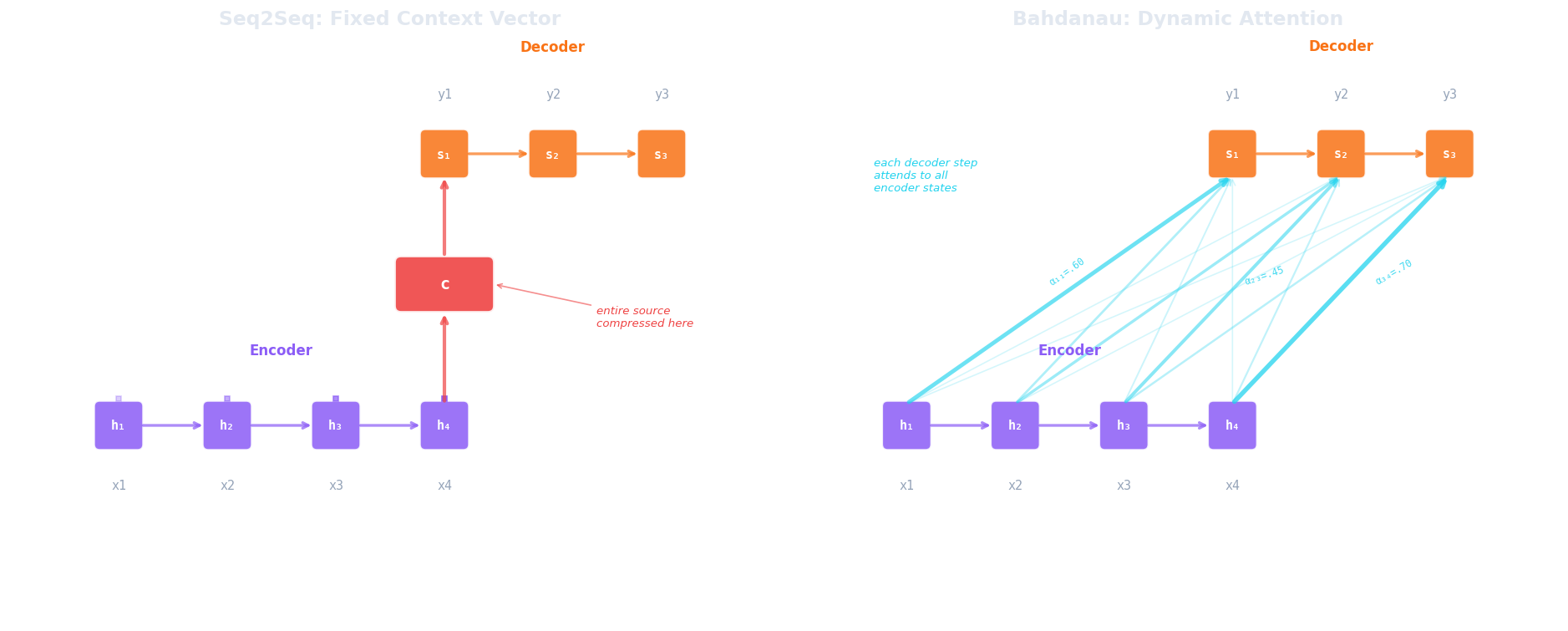
El avance vino de Bahdanau, Cho & Bengio (2014) , quienes propusieron un cambio simple pero poderoso: en lugar de comprimir toda la fuente en un solo vector, permitir que el decoder consulte todos los estados ocultos del encoder en cada paso de decodificación, y aprenda en cuáles enfocarse. El vector de contexto ya no es fijo; se recalcula en cada paso temporal del decoder como una combinación ponderada de los estados del encoder.
En cada paso $i$ del decoder, el modelo calcula un puntaje de alineación $e_{ij}$ entre el estado actual del decoder $s_{i-1}$ y cada estado oculto del encoder $h_j^{\text{enc}}$, y luego normaliza estos puntajes en pesos de atención $\alpha_{ij}$ con un softmax:
donde $a$ es una pequeña red de alineación aprendida (típicamente una sola capa oculta con activación $\tanh$). El vector de contexto $c_i$ para el paso $i$ del decoder es entonces la suma ponderada de todos los estados ocultos del encoder:
Veamos por qué esto resuelve el problema. Cuando $\alpha_{i3}$ es grande y el resto es pequeño, $c_i$ es aproximadamente $h_3^{\text{enc}}$ (el decoder está mirando directamente al tercer token fuente). Sin compresión a través de una cadena de pasos de recurrencia, sin pérdida de información temprana. El decoder puede atender a la posición 1 al generar la primera palabra objetivo y a la posición 40 al generar la última, cada vez extrayendo información directamente del estado del encoder relevante.
Consideremos los casos extremos. Si todos los $\alpha_{ij}$ son iguales ($\frac{1}{T}$ cada uno), el vector de contexto es un promedio simple de todos los estados del encoder, que es aproximadamente lo que hacía el vector de contexto fijo (resumiendo todo por igual). Si exactamente un $\alpha_{ij} = 1$ y el resto son 0, el decoder está realizando una consulta dura, leyendo una única posición del encoder. En la práctica, los pesos aprendidos caen en algún punto entre estos extremos, seleccionando suavemente unas pocas posiciones relevantes mientras ignoran el resto.
Los resultados fueron inmediatos y llamativos. En traducción de inglés a francés, el modelo con atención revirtió la degradación dependiente de la longitud que había afectado a seq2seq: los puntajes BLEU se mantuvieron estables incluso a medida que la longitud de la oración crecía, porque el decoder ya no estaba limitado a un único vector. Los pesos de atención también resultaron ser interpretables — al traducir una palabra, el modelo aprendía a atender a la palabra fuente correspondiente (o palabras), produciendo matrices de alineación suave que se asemejaban estrechamente a las alineaciones duras de palabras utilizadas en la traducción automática estadística tradicional.
Pero la atención de Bahdanau tiene una limitación que es fácil pasar por alto. El encoder sigue siendo un RNN. Cada $h_j^{\text{enc}}$ se calcula secuencialmente, por lo que construir las representaciones del encoder toma $O(T)$ pasos seriales. El mecanismo de atención permite al decoder acceder directamente a cualquier posición del encoder, pero el encoder mismo aún comprime la información paso a paso. De manera similar, el decoder sigue siendo autoregresivo, y cada estado del decoder depende del anterior. La atención resolvió el problema de acceso a la información (el decoder puede verlo todo) pero no el problema de computación (todavía no podemos paralelizar el procesamiento secuencial). Esa limitación impulsaría el siguiente paso: ¿qué pasaría si eliminamos el RNN por completo y construimos un modelo solo con atención?
De Atención-sobre-RNNs a Attention-Is-All-You-Need
Después del artículo de Bahdanau, la atención se convirtió en un complemento estándar de los modelos de secuencias. Luong et al. (2015) simplificaron la función de alineación (usando un producto punto en lugar de una red aprendida), y la atención fue rápidamente adoptada en reconocimiento de voz, descripción de imágenes y resumen. Pero en todos los casos, la atención se colocaba sobre un RNN subyacente. La recurrencia permanecía.
Esto importa por dos razones prácticas. Primero, los RNNs son inherentemente secuenciales: no podemos calcular $h_t$ hasta que $h_{t-1}$ esté listo, lo que significa que no podemos paralelizar a través de los pasos temporales durante el entrenamiento. Las GPUs modernas son procesadores masivamente paralelos, pero un RNN las obliga a procesar tokens uno a la vez, desperdiciando la mayor parte de su capacidad de cómputo. Segundo, incluso con atención, el estado oculto del RNN sigue sirviendo como la representación principal en cada posición, y esa representación se construye a través de la misma recurrencia que causa las dificultades de largo alcance que discutimos anteriormente.
La pregunta que Vaswani et al. (2017) plantearon fue radical: ¿qué pasa si eliminamos el RNN y usamos solo atención? En lugar de construir representaciones a través de recurrencia, cada posición atiende a todas las demás posiciones directamente, en paralelo. La entrada se procesa de una sola vez (todas las posiciones simultáneamente), con la atención como único mecanismo para que las posiciones intercambien información. Esta es la arquitectura Transformer .
Eliminar la recurrencia resuelve ambos problemas a la vez. Sin la dependencia secuencial entre estados ocultos, cada posición puede calcularse en paralelo durante el entrenamiento, lo que hace que los transformers sean dramáticamente más rápidos en hardware GPU. Y porque cada posición puede atender directamente a todas las demás posiciones (sin pasar por estados ocultos intermedios), las dependencias de largo alcance ya no requieren que la información sobreviva una cadena de transformaciones. La posición 1 y la posición 200 están conectadas a través de una única operación de atención.
El siguiente artículo desglosa exactamente cómo funciona este mecanismo de atención. Examinaremos el marco de query-key-value que hace posible la auto-atención, recorreremos la fórmula del producto punto escalado y veremos por qué una operación matemática aparentemente simple (proyectar, producto punto, softmax, suma ponderada) es lo suficientemente poderosa como para reemplazar la recurrencia por completo.
Cuestionario
Pon a prueba tu comprensión de la motivación detrás de los mecanismos de atención.
¿Cuál es el problema central de los modelos encoder-decoder seq2seq básicos?
¿Cómo resuelve la atención de Bahdanau el cuello de botella de información?
¿Qué limitación de la atención de Bahdanau abordó la arquitectura Transformer?
Si todos los pesos de atención α_ij son iguales (1/T cada uno), ¿qué aproxima el vector de contexto?