De la comprensión a la generación
El encoder que construimos en el artículo anterior es poderoso para comprender texto, pero no puede generar texto nuevo. Toma una secuencia de entrada y produce una secuencia de la misma longitud como salida, con cada posición enriquecida por contexto bidireccional. Si le pedimos que continúe una oración, no tiene ningún mecanismo para producir un token a la vez, condicionando cada nuevo token en los que vinieron antes.
La generación requiere una estructura diferente. Necesitamos un modelo que, dados los tokens $x_1, x_2, \ldots, x_t$, prediga la distribución de probabilidad sobre el siguiente token $x_{t+1}$, muestree o seleccione de esa distribución, agregue el resultado y repita. Esto es la generación autoregressive , y la arquitectura que la soporta es el decoder . El decoder usa los mismos bloques de construcción que el encoder (multi-head attention, add-and-norm, red feed-forward), pero con un cambio crítico: la self-attention es causal . Un token en la posición $t$ solo puede atender a las posiciones $1, 2, \ldots, t$, nunca a posiciones futuras. Esta es la máscara causal que construimos en el artículo 3, y asegura que la predicción del modelo para la posición $t+1$ dependa solo de la información que realmente estaría disponible en el momento de la generación.
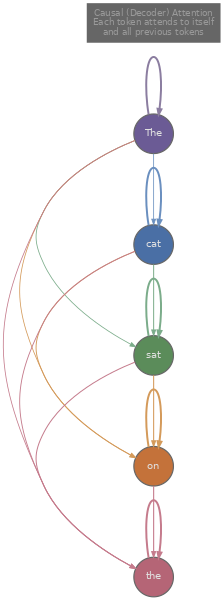
El modelo canónico decoder-only es GPT (Radford et al., 2018) , que demostró que un transformer decoder entrenado en un gran corpus con un simple objetivo de predicción del siguiente token podía luego ser ajustado (fine-tuned) para una amplia gama de tareas posteriores. El objetivo de entrenamiento es directo: dada una secuencia de tokens, maximizar la log-probabilidad de cada token condicionado en los tokens precedentes.
Cada término en esta suma le pide al modelo que asigne alta probabilidad al token que realmente viene a continuación. Si el modelo está seguro y es correcto, $P(x_t \mid \ldots)$ está cerca de 1 y $-\log P$ está cerca de 0. Si el modelo se sorprende por el token siguiente real, $P(x_t \mid \ldots)$ es pequeño y la pérdida es grande. Promediar sobre todas las $T$ posiciones en la secuencia significa que cada posición contribuye una señal de entrenamiento, lo que hace que el objetivo sea altamente eficiente en datos comparado con MLM (donde solo el 15% de las posiciones producen una pérdida).
Durante el entrenamiento, podemos calcular la pérdida para todas las posiciones en paralelo usando la máscara causal. El modelo procesa toda la secuencia de una vez, la máscara asegura que la posición $t$ solo vea las posiciones $\leq t$, y calculamos la pérdida en todas las posiciones simultáneamente. Esto se llama teacher forcing : alimentamos los tokens de referencia (ground-truth) en cada posición en lugar de las propias predicciones del modelo, lo que evita la acumulación de errores y permite un cálculo eficiente por lotes. Sin embargo, en el momento de la inferencia, debemos generar un token a la vez, retroalimentarlo y repetir.
¿Cómo elegimos el siguiente token?
Una vez que el modelo produce una distribución de probabilidad sobre el vocabulario para la posición $t+1$, necesitamos una estrategia para elegir qué token emitir realmente. Esta elección importa más de lo que podría parecer: el mismo modelo puede producir texto repetitivo y aburrido o texto creativo y diverso dependiendo enteramente de la estrategia de muestreo.
El enfoque más simple es la decodificación greedy : siempre elegir el token con la mayor probabilidad. Es rápido (no hay aleatoriedad que gestionar) y determinista (el mismo prompt siempre produce la misma salida), pero tiende a producir texto repetitivo y genérico. Debido a que el token de mayor probabilidad en cada paso suele ser una palabra común y segura, la decodificación greedy a menudo cae en bucles o produce salida insulsa que nunca toma riesgos.
Podemos implementar la decodificación greedy y las alternativas de muestreo en unas pocas líneas cada una. El código a continuación muestra las cuatro estrategias operando sobre el mismo vector de logits.
import math
import random
random.seed(42)
# Simulated raw logits for a vocabulary of 8 tokens
vocab = ["the", "cat", "sat", "on", "a", "dog", "mat", "hat"]
logits = [2.0, 1.5, 0.8, 0.3, 0.1, 1.2, 0.6, 0.9]
def softmax(logits):
m = max(logits)
exps = [math.exp(x - m) for x in logits]
s = sum(exps)
return [e / s for e in exps]
# 1. Greedy: pick the highest-probability token
probs = softmax(logits)
greedy_idx = probs.index(max(probs))
print(f"Greedy: '{vocab[greedy_idx]}' (p={probs[greedy_idx]:.3f})")
# 2. Temperature: scale logits before softmax
def sample_with_temperature(logits, T):
scaled = [l / T for l in logits]
probs = softmax(scaled)
r = random.random()
cumulative = 0.0
for i, p in enumerate(probs):
cumulative += p
if r < cumulative:
return i, probs
return len(probs) - 1, probs
idx_low, p_low = sample_with_temperature(logits, T=0.3)
idx_high, p_high = sample_with_temperature(logits, T=2.0)
print(f"Temp=0.3: '{vocab[idx_low]}' (top prob={max(p_low):.3f}, nearly greedy)")
print(f"Temp=2.0: '{vocab[idx_high]}' (top prob={max(p_high):.3f}, very spread out)")
# 3. Top-k: sample from the k most probable tokens
def sample_top_k(logits, k):
indexed = sorted(enumerate(logits), key=lambda x: -x[1])[:k]
top_logits = [l for _, l in indexed]
top_indices = [i for i, _ in indexed]
probs = softmax(top_logits)
r = random.random()
cumulative = 0.0
for i, p in enumerate(probs):
cumulative += p
if r < cumulative:
return top_indices[i], probs, top_indices
return top_indices[-1], probs, top_indices
idx_k, probs_k, kept_k = sample_top_k(logits, k=3)
print(f"Top-k=3: '{vocab[idx_k]}' (candidates: {[vocab[i] for i in kept_k]})")
# 4. Top-p (nucleus): sample from smallest set with cumulative prob >= p
def sample_top_p(logits, p_threshold):
probs = softmax(logits)
indexed = sorted(enumerate(probs), key=lambda x: -x[1])
cumulative = 0.0
nucleus = []
for i, p in indexed:
cumulative += p
nucleus.append((i, p))
if cumulative >= p_threshold:
break
# Re-normalise within the nucleus
total = sum(p for _, p in nucleus)
r = random.random()
cumulative = 0.0
for i, p in nucleus:
cumulative += p / total
if r < cumulative:
return i, [vocab[idx] for idx, _ in nucleus]
return nucleus[-1][0], [vocab[idx] for idx, _ in nucleus]
idx_p, nucleus_tokens = sample_top_p(logits, p_threshold=0.8)
print(f"Top-p=0.8: '{vocab[idx_p]}' (nucleus: {nucleus_tokens})")Analicemos qué hace realmente cada estrategia con la distribución.
Temperature divide cada logit por un escalar $T$ antes de softmax. Cuando $T \to 0$, la división amplifica las diferencias entre logits tanto que el logit más grande domina completamente, recuperando la decodificación greedy en el límite. Cuando $T \to \infty$, todos los logits se vuelven $\approx 0$ después de la división, y softmax produce una distribución casi uniforme, por lo que el modelo muestrea casi al azar. En la práctica, valores entre 0.7 y 1.0 son comunes para generación coherente, mientras que valores por encima de 1.0 fomentan la creatividad a costa de ocasionales incoherencias.
Muestreo top-k (Fan et al., 2018) restringe el conjunto de candidatos a los $k$ tokens con las mayores probabilidades, pone a cero todo lo demás y re-normaliza. Esto evita que el modelo muestree tokens de probabilidad extremadamente baja (que tienden a ser incoherentes), pero el $k$ fijo es una debilidad: cuando el modelo está seguro, incluso $k = 10$ podría incluir tokens basura que diluyen la calidad; cuando la distribución es plana y el modelo está genuinamente inseguro, $k = 10$ podría excluir continuaciones perfectamente razonables.
Muestreo nucleus (top-p) (Holtzman et al., 2019) resuelve esto adaptando el tamaño del conjunto de candidatos dinámicamente. En lugar de fijar $k$, ordenamos los tokens por probabilidad descendente y seguimos agregando tokens al nucleus hasta que su probabilidad acumulada alcanza un umbral $p$ (comúnmente 0.9 o 0.95). Cuando el modelo está seguro, el nucleus podría contener solo 2 o 3 tokens; cuando está inseguro, podría contener cientos. Esta adaptabilidad tiende a producir texto más natural que el top-k fijo, y el muestreo nucleus se ha convertido en la estrategia predeterminada en la mayoría de las APIs de modelos de lenguaje en producción.
¿Cómo sabemos si el modelo es bueno?
Tenemos un modelo que genera texto y un conjunto de estrategias para elegir tokens. Pero, ¿cómo cuantificamos si el modelo en sí (independiente de la estrategia de muestreo) ha aprendido bien el lenguaje? La métrica estándar para modelos de lenguaje es la perplejidad (perplexity) , que mide cuán sorprendido está el modelo ante un conjunto de prueba reservado.
La perplejidad se define como la exponencial del promedio de la log-verosimilitud negativa:
La expresión dentro de la exponencial es exactamente la pérdida de entropía cruzada con la que entrenamos, así que la perplejidad es $e^{\text{loss}}$. Esta transformación del espacio logarítmico de vuelta al espacio de probabilidad le da a la perplejidad una interpretación directa: una perplejidad de $k$ significa que el modelo está, en promedio, tan inseguro como si estuviera eligiendo uniformemente entre $k$ opciones en cada paso. Si un modelo logra perplejidad 20 en un conjunto de prueba, está tan sorprendido como si tuviera que elegir entre 20 tokens igualmente probables en cada posición.
Para ver por qué menor es mejor, consideremos los extremos. Si el modelo asigna probabilidad 1.0 al token correcto en cada posición (un modelo perfecto), la pérdida es $0$ y la perplejidad es $e^0 = 1$. Si el modelo asigna probabilidad igual $1/V$ a cada token en un vocabulario de tamaño $V$ (un modelo que no ha aprendido nada), la pérdida es $\log V$ y la perplejidad es $V$, que para el vocabulario de GPT-2 es alrededor de 50,257. Los modelos reales caen entre estos límites, y mejoras de 25 a 20 de perplejidad típicamente corresponden a una calidad de generación notablemente mejor.
Podemos calcular la perplejidad a partir de un conjunto de probabilidades por token. El código a continuación simula una secuencia corta y recorre el cálculo paso a paso.
import math
# Simulated model probabilities for each token in a 10-token sequence
# Higher values = model was more confident about the correct token
token_probs = [0.85, 0.72, 0.30, 0.95, 0.60, 0.45, 0.88, 0.15, 0.70, 0.55]
tokens = ["The", "cat", "sat", "on", "the", "old", "mat", "and", "then", "left"]
# Per-token loss and perplexity
total_nll = 0.0
print("Token-level breakdown:")
for i, (tok, p) in enumerate(zip(tokens, token_probs)):
nll = -math.log(p)
total_nll += nll
print(f" '{tok}': P={p:.2f} -> -log P = {nll:.3f}")
avg_nll = total_nll / len(tokens)
ppl = math.exp(avg_nll)
print(f"\nAverage NLL (cross-entropy loss): {avg_nll:.4f}")
print(f"Perplexity = exp({avg_nll:.4f}) = {ppl:.2f}")
print(f"\nInterpretation: the model is as uncertain as choosing")
print(f"uniformly among ~{ppl:.0f} tokens at each step.")Observa cómo el token "and" (con $P = 0.15$) contribuye una pérdida mucho mayor que "on" (con $P = 0.95$). La perplejidad está dominada por los tokens que el modelo encuentra más sorprendentes, razón por la cual las palabras raras, los nombres propios y las transiciones inesperadas tienden a ser las partes más difíciles de un conjunto de prueba.
Más allá de la perplejidad, los modelos de lenguaje a menudo se evalúan en benchmarks posteriores que prueban capacidades específicas. HellaSwag (Zellers et al., 2019) evalúa el razonamiento de sentido común presentando un escenario y cuatro posibles continuaciones, pidiendo al modelo que elija la más plausible. MMLU (Hendrycks et al., 2020) cubre 57 materias desde matemáticas elementales hasta derecho profesional, midiendo cuánto conocimiento del mundo ha absorbido el modelo. Estos benchmarks complementan la perplejidad porque un modelo puede tener baja perplejidad (predice bien el texto) mientras aún falla en tareas de razonamiento que requieren combinar conocimiento entre dominios.
¿Cómo debería verse el entrenamiento?
Pre-entrenar un modelo de lenguaje decoder significa ejecutar el objetivo de predicción del siguiente token sobre miles de millones de tokens durante muchos miles de pasos de gradiente. Las curvas de pérdida durante este proceso tienen una forma característica que vale la pena entender, porque reconocer cómo se ve un entrenamiento saludable e insalubre ayuda a diagnosticar problemas tempranamente.
La pérdida de entrenamiento comienza alta (el modelo es aleatorio, así que sus predicciones por token son casi uniformes a lo largo del vocabulario) y cae abruptamente en los primeros miles de pasos a medida que el modelo aprende sintaxis básica, frecuencias de palabras comunes y dependencias de corto alcance. El descenso luego se aplana gradualmente a medida que el modelo pasa de patrones fáciles (predecir "the" después de "in") a patrones más difíciles (predecir el nombre correcto en "The 44th president of the United States was ___"). Una ejecución de entrenamiento típica a escala GPT-2 podría ver la pérdida de entrenamiento caer de ~10 a ~3 durante toda la ejecución, correspondiendo a una reducción de perplejidad de ~22,000 a ~20.
La pérdida de validación (calculada sobre datos reservados en los que el modelo nunca entrena) debería seguir de cerca la pérdida de entrenamiento durante un entrenamiento saludable. La brecha entre ellas revela la generalización: si la pérdida de entrenamiento sigue disminuyendo pero la pérdida de validación se estabiliza o aumenta, el modelo está memorizando datos de entrenamiento en lugar de aprender patrones generalizables. Esto es sobreajuste (overfitting), y tiende a ocurrir cuando el modelo es demasiado grande para la cantidad de datos de entrenamiento o cuando el entrenamiento se ejecuta durante demasiadas épocas.
Las leyes de escalado (Kaplan et al., 2020) mostraron que la pérdida de validación sigue relaciones de ley de potencias con el tamaño del modelo, el tamaño del dataset y el presupuesto de cómputo: duplicar los parámetros y la pérdida disminuye una cantidad predecible. Chinchilla (Hoffmann et al., 2022) refinó esto mostrando que muchos modelos estaban sub-entrenados (demasiados parámetros, no suficientes datos), y que la proporción óptima es aproximadamente 20 tokens de datos de entrenamiento por parámetro. Un modelo de 1B parámetros debería ver alrededor de 20B tokens, y un modelo de 70B debería ver alrededor de 1.4T tokens para un entrenamiento óptimo en cómputo.
El siguiente código simula cómo se ven típicamente las curvas saludables de pérdida de entrenamiento y validación, junto con un escenario de sobreajuste donde el modelo es demasiado grande para los datos.
import math, json
import js
steps = list(range(0, 5001, 100))
def healthy_train(s):
return 3.5 * math.exp(-s / 800) + 2.8 + 0.15 * math.exp(-s / 3000)
def healthy_val(s):
return 3.5 * math.exp(-s / 800) + 2.85 + 0.15 * math.exp(-s / 3000)
def overfit_train(s):
return 3.5 * math.exp(-s / 600) + 2.5 + 0.2 * math.exp(-s / 2000)
def overfit_val(s):
base = 3.5 * math.exp(-s / 800) + 2.9 + 0.15 * math.exp(-s / 3000)
if s > 2000:
base += 0.0002 * (s - 2000)
return base
train_h = [round(healthy_train(s), 3) for s in steps]
val_h = [round(healthy_val(s), 3) for s in steps]
train_o = [round(overfit_train(s), 3) for s in steps]
val_o = [round(overfit_val(s), 3) for s in steps]
plot_data = [
{
"title": "Healthy Training (enough data)",
"x_label": "Steps",
"y_label": "Loss",
"x_data": steps,
"lines": [
{"label": "Train loss", "data": train_h, "color": "#3b82f6"},
{"label": "Val loss", "data": val_h, "color": "#ef4444"},
]
},
{
"title": "Overfitting (too little data)",
"x_label": "Steps",
"y_label": "Loss",
"x_data": steps,
"lines": [
{"label": "Train loss", "data": train_o, "color": "#3b82f6"},
{"label": "Val loss", "data": val_o, "color": "#ef4444"},
]
}
]
js.window.py_plot_data = json.dumps(plot_data)En el caso saludable, la pérdida de entrenamiento y validación descienden juntas y casi convergen, lo que significa que el modelo está aprendiendo patrones que generalizan más allá del conjunto de entrenamiento. En el caso de sobreajuste, la pérdida de entrenamiento continúa cayendo (el modelo sigue memorizando), pero la pérdida de validación gira hacia arriba después del paso 2000, señalando que las predicciones del modelo sobre datos no vistos están empeorando. En la práctica, es por esto que monitoreamos la pérdida de validación y detenemos el entrenamiento (o reducimos la tasa de aprendizaje) cuando deja de mejorar.
Quiz
Pon a prueba tu comprensión del decoder, las estrategias de muestreo y la evaluación.
¿Por qué el decoder usa causal self-attention en lugar de bidireccional?
¿Qué sucede con la distribución softmax cuando la temperature T se acerca a 0?
Un modelo de lenguaje logra perplejidad 50 en un conjunto de prueba. ¿Qué significa esto?
¿Qué ventaja tiene el muestreo nucleus (top-p) sobre el muestreo top-k fijo?
Si la pérdida de validación aumenta mientras la pérdida de entrenamiento continúa disminuyendo, ¿qué está sucediendo?