¿Por qué una sola cabeza se queda corta?
A estas alturas tenemos un mecanismo completo de attention de una sola cabeza: los queries y keys producen una matriz de scores, escalamos por $\sqrt{d_k}$, aplicamos softmax y usamos el resultado para ponderar los values. Ese mecanismo funciona, pero obliga a cada token a resumir todo lo que necesita de la secuencia en un único patrón de attention. Consideremos la palabra "bank" en la oración "The bank by the river issued a statement." Para entender esta oración, "bank" necesita atender a "river" (para resolver que se trata de una ribera, no de una institución financiera) y simultáneamente atender a "issued" (para captar que el sujeto del verbo es "bank"). Una sola distribución de attention es una distribución de probabilidad sobre posiciones, por lo que los pesos de attention deben sumar 1, y enfocarse fuertemente en "river" necesariamente quita peso de "issued."
Este no es un caso extremo artificial. El lenguaje constantemente requiere rastrear múltiples relaciones a la vez: dependencias sintácticas (¿cuál es el sujeto de este verbo?), similitud semántica (¿qué palabras comparten significado?), correferencia (¿a qué sustantivo se refiere este pronombre?) y proximidad posicional (¿qué vino justo antes de esta palabra?). Una sola cabeza de attention comprime todo esto en un único promedio ponderado, lo que obliga al modelo a comprometerse entre demandas competidoras.
La solución propuesta en (Vaswani et al., 2017) es ejecutar varias cabezas de attention en paralelo, cada una con sus propias proyecciones aprendidas, de modo que diferentes cabezas puedan especializarse en diferentes tipos de relaciones. Las salidas luego se concatenan y se proyectan de vuelta a la dimensión del modelo. Esto es la attention multi-cabeza .
¿Cómo divide el modelo en múltiples cabezas?
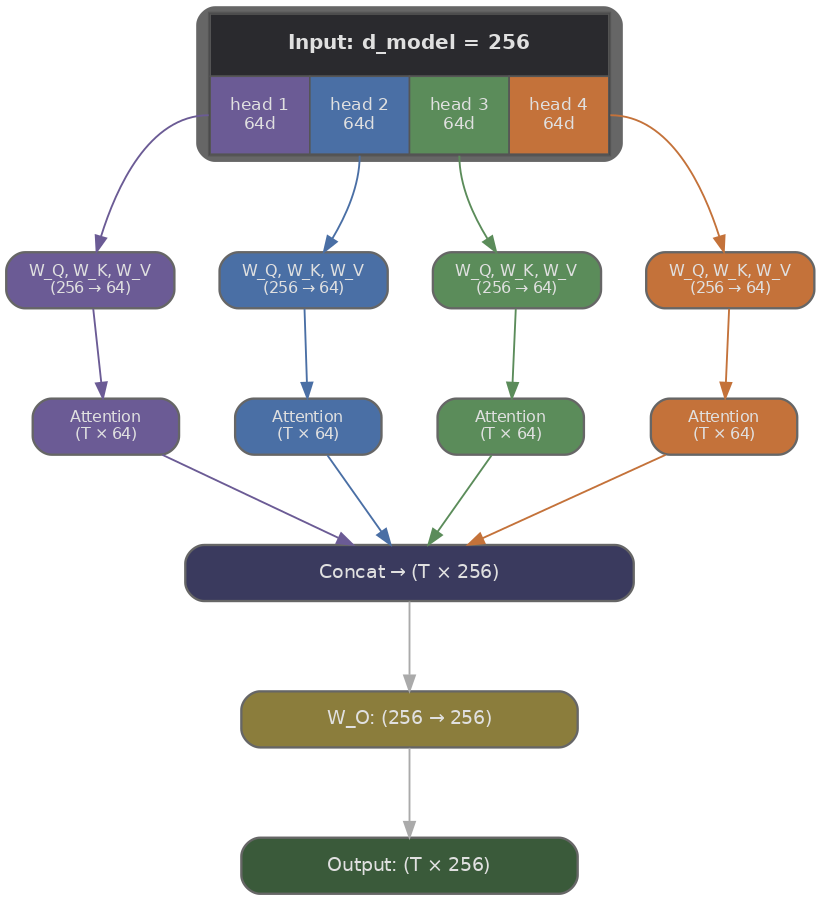
Supongamos que la dimensión de nuestro modelo es $d_{\text{model}} = 512$ y queremos $H = 8$ cabezas. En lugar de dar a cada cabeza sus propias proyecciones de tamaño completo (lo que multiplicaría el conteo de parámetros por 8), dividimos la representación: cada cabeza opera sobre una porción de tamaño $d_k = d_{\text{model}} / H = 64$. El cómputo total permanece aproximadamente igual al de la attention de una sola cabeza sobre el $d_{\text{model}}$ completo, porque ejecutamos $H$ attentions más pequeñas en lugar de una grande.
Cada cabeza $i$ tiene sus propias matrices de proyección $W_i^Q$, $W_i^K$ y $W_i^V$, cada una de forma $(d_{\text{model}}, d_k)$. Dada una entrada $X$ de forma $(T, d_{\text{model}})$ donde $T$ es la longitud de la secuencia, las proyecciones para la cabeza $i$ se calculan de la siguiente manera.
Cada cabeza luego ejecuta la attention de producto punto escalado estándar de forma independiente, produciendo una salida de forma $(T, d_k)$. Como hay $H$ cabezas, obtenemos $H$ salidas de forma $(T, d_k)$, que concatenamos a lo largo de la última dimensión para recuperar la forma $(T, d_{\text{model}})$. Una proyección de salida final $W^O$ de forma $(d_{\text{model}}, d_{\text{model}})$ mezcla la información entre cabezas.
Tracemos las formas a través de un ejemplo concreto con $d_{\text{model}} = 512$, $H = 8$, $d_k = 64$ y una secuencia de $T = 10$ tokens:
- Entrada: $X$ es $(10, 512)$.
- Proyección por cabeza: $Q_i = X W_i^Q$ mapea $(10, 512) \times (512, 64) \to (10, 64)$. Lo mismo para $K_i$ y $V_i$.
- Scores de attention por cabeza: $Q_i K_i^\top$ mapea $(10, 64) \times (64, 10) \to (10, 10)$. Cada cabeza produce su propia matriz de attention $T \times T$.
- Salida por cabeza: $\text{softmax}(\ldots) \, V_i$ mapea $(10, 10) \times (10, 64) \to (10, 64)$.
- Concatenación: apilamos las 8 cabezas a lo largo del último eje: $(10, 64) \times 8 \to (10, 512)$.
- Proyección de salida: $W^O$ mapea $(10, 512) \times (512, 512) \to (10, 512)$.
La salida tiene exactamente la misma forma que la entrada, $(T, d_{\text{model}})$, lo que significa que la attention multi-cabeza es un reemplazo directo de la attention de una sola cabeza. Esta propiedad de preservar la forma también importa para apilar capas, ya que la salida de un bloque de attention se convierte en la entrada del siguiente.
¿Cómo se ve esto en código?
En la práctica, no iteramos sobre las cabezas una por una. En su lugar, proyectamos el $d_{\text{model}}$ completo para todas las cabezas a la vez usando una única matriz de pesos de forma $(d_{\text{model}}, d_{\text{model}})$, luego redimensionamos el resultado para separar las cabezas. Esto es matemáticamente idéntico a tener $H$ proyecciones separadas de $(d_{\text{model}}, d_k)$, pero se ejecuta en una sola multiplicación de matrices en lugar de $H$, lo cual es mucho más rápido en GPUs.
La siguiente implementación mantiene las cosas explícitas para que podamos ver cada paso claramente. Proyectamos todas las cabezas a la vez, redimensionamos para separarlas, ejecutamos attention por cabeza, concatenamos y aplicamos la proyección de salida.
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
# One big projection for all heads, then we reshape
self.W_Q = nn.Linear(d_model, d_model, bias=False)
self.W_K = nn.Linear(d_model, d_model, bias=False)
self.W_V = nn.Linear(d_model, d_model, bias=False)
self.W_O = nn.Linear(d_model, d_model, bias=False)
def forward(self, X, mask=None):
B, T, _ = X.shape # batch, sequence length, d_model
# Project all heads at once: (B, T, d_model) -> (B, T, d_model)
Q = self.W_Q(X)
K = self.W_K(X)
V = self.W_V(X)
# Reshape to (B, num_heads, T, d_k) so each head has its own slice
Q = Q.view(B, T, self.num_heads, self.d_k).transpose(1, 2)
K = K.view(B, T, self.num_heads, self.d_k).transpose(1, 2)
V = V.view(B, T, self.num_heads, self.d_k).transpose(1, 2)
# Scaled dot-product attention per head
# scores: (B, num_heads, T, T)
scores = (Q @ K.transpose(-2, -1)) / (self.d_k ** 0.5)
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
attn_weights = F.softmax(scores, dim=-1)
# Weighted sum of values: (B, num_heads, T, d_k)
head_outputs = attn_weights @ V
# Concatenate heads: (B, T, d_model)
concat = head_outputs.transpose(1, 2).contiguous().view(B, T, self.d_model)
# Final projection mixes information across heads
return self.W_O(concat)
# --- Quick shape check ---
d_model, num_heads, T, batch = 512, 8, 10, 2
mha = MultiHeadAttention(d_model, num_heads)
X = torch.randn(batch, T, d_model)
output = mha(X)
print(f"Input shape: {X.shape}") # (2, 10, 512)
print(f"Output shape: {output.shape}") # (2, 10, 512)
print(f"Heads: {num_heads}, head dim: {d_model // num_heads}")
print(f"Parameters: {sum(p.numel() for p in mha.parameters()):,}")
Algunas cosas a notar en el código. Las llamadas a
view
y
transpose
son las operaciones clave:
view(B, T, num_heads, d_k)
divide la última dimensión en cabezas separadas, y
transpose(1, 2)
mueve la dimensión de cabeza antes de la dimensión de secuencia para que la multiplicación matricial por lotes
Q @ K.transpose(-2, -1)
ejecute la attention independientemente para cada cabeza en paralelo. Después de la attention, revertimos la operación con
transpose(1, 2).contiguous().view(B, T, d_model)
para concatenar las cabezas de nuevo.
¿Qué aprenden realmente las diferentes cabezas?
Nada en la arquitectura obliga a las cabezas a especializarse, pero empíricamente tienden a hacerlo. Varios estudios han analizado qué patrones emergen en transformers entrenados, y los hallazgos son notablemente consistentes.
Clark et al. (2019) analizaron las cabezas de attention de BERT y encontraron que las cabezas individuales a menudo aprenden roles interpretables. Algunas cabezas rastrean dependencias sintácticas (la cabeza atiende consistentemente de un verbo a su sujeto, independientemente de la distancia), mientras que otras se enfocan en patrones posicionales (atender al token anterior o al siguiente). Voita et al. (2019) ("Analyzing Multi-Head Self-Attention") fueron más allá e identificaron tres tipos dominantes de cabeza en modelos de traducción inglés-ruso: cabezas posicionales (que atienden a una posición adyacente), cabezas sintácticas (que atienden a lo largo de las aristas del árbol de dependencias), y cabezas de palabras raras (que atienden a los tokens menos frecuentes en la oración, que tienden a portar la información más desambiguadora).
Esta especialización es la razón por la que la attention multi-cabeza supera a simplemente aumentar $d_k$ en una sola cabeza. Una sola cabeza más grande tiene más capacidad, pero sigue produciendo un solo patrón de attention por token. Múltiples cabezas permiten al modelo enrutar diferentes tipos de información a través de diferentes canales simultáneamente, y la proyección de salida $W^O$ aprende a combinarlos. En términos de teoría de grafos (recordando nuestro enfoque anterior de la matriz de attention como una matriz de adyacencia), cada cabeza define un grafo diferente sobre el mismo conjunto de tokens, y el modelo lee todos estos grafos a la vez.
Quiz
Pon a prueba tu comprensión de la attention multi-cabeza y cómo extiende el mecanismo de una sola cabeza.
Si d_model = 768 y usamos 12 cabezas de attention, ¿cuál es la dimensión de los vectores query, key y value de cada cabeza?
¿Por qué la attention multi-cabeza usa una proyección de salida W_O después de concatenar las cabezas?
¿Cuál es la principal ventaja de la attention multi-cabeza sobre la attention de una sola cabeza con el mismo d_model?
¿Cómo se compara el conteo total de parámetros de la attention multi-cabeza con la attention de una sola cabeza (asumiendo el mismo d_model)?