¿Por qué un decoder no puede mirar hacia adelante?
El artículo anterior describió la attention como un mecanismo donde cada posición puede atender a todas las demás posiciones. Esto funciona perfectamente cuando estamos codificando una entrada (como BERT procesando una oración para clasificación), porque la entrada completa está disponible de una vez y cada token se beneficia de ver el contexto completo en ambas direcciones. Pero cuando un modelo está generando texto — prediciendo el siguiente token dado todo lo anterior — enfrentamos una restricción fundamental: el modelo no puede ver el futuro.
Consideremos un modelo de lenguaje siendo entrenado con la oración "the cat sat on the mat." En la posición 3, el modelo debería predecir "sat" a partir del contexto "the cat". Si la posición 3 pudiera atender a la posición 4 ("on"), la posición 5 ("the") y la posición 6 ("mat"), la tarea de predicción se vuelve trivial (el modelo simplemente copia la respuesta en lugar de aprender a predecirla). Durante la generación en tiempo de inferencia, las posiciones 4, 5 y 6 ni siquiera existen todavía cuando estamos produciendo la posición 3, así que permitir attention a esas posiciones durante el entrenamiento crearía una discrepancia entre las condiciones de entrenamiento e inferencia.
Esto no es solo una preocupación práctica sobre hacer trampa en la loss de entrenamiento. Es arquitectónicamente necesario para que la generación autoregresiva funcione en absoluto. Cuando generamos token por token en tiempo de inferencia, cada nuevo token se produce condicionado únicamente a los tokens anteriores. Si el modelo fuera entrenado con acceso a tokens futuros, las representaciones que aprendió dependerían de información que simplemente no está disponible durante la generación, y las salidas del modelo serían incoherentes.
Así que necesitamos una forma de imponer la restricción de que la posición $i$ solo pueda atender a posiciones $j \leq i$. Podríamos lograr esto ejecutando literalmente la attention $T$ veces por separado (una vez por posición, cada vez incluyendo solo los tokens apropiados), pero eso destruiría el paralelismo que hace rápidos a los transformers. En su lugar, usamos una máscara causal (una operación única que bloquea las posiciones futuras mientras mantiene toda la computación paralelizada).
¿Cómo funciona realmente la máscara?
Recordemos del artículo anterior que los scores de attention crudos forman una matriz $T \times T$ $S = QK^\top / \sqrt{d_k}$, donde $S_{ij}$ es el score entre el query de la posición $i$ y el key de la posición $j$. Antes de aplicar softmax, sumamos una matriz de máscara $M$ a estos scores:
La máscara $M \in \mathbb{R}^{T \times T}$ se define como:
Para una secuencia de 4 tokens, la máscara se ve así:
Cuando sumamos $-\infty$ a un score y luego aplicamos softmax, el exponente $e^{-\infty} = 0$, por lo que esa posición recibe exactamente cero peso de attention. Las posiciones permitidas (donde $M_{ij} = 0$) pasan sin cambios. Después del softmax, cada fila sigue sumando 1, pero la masa de probabilidad se distribuye solo sobre la posición actual y las anteriores.
Consideremos qué ocurre fila por fila. La fila 1 (posición 0, el primer token) tiene $-\infty$ en todas partes excepto la columna 0, así que después del softmax se convierte en $[1, 0, 0, 0]$ (el primer token solo puede atender a sí mismo). La fila 2 distribuye su peso entre las columnas 0 y 1. La fila 3 distribuye entre las columnas 0, 1 y 2. La fila 4 atiende a todas las posiciones. Cada posición sucesiva tiene acceso a estrictamente más contexto que la anterior.
La implementación es directa. Podemos construir la máscara como una matriz triangular inferior de unos, invertirla y multiplicar por un número negativo grande.
import numpy as np
T = 5 # sequence length
# Lower-triangular matrix: 1 where attention is allowed, 0 where blocked
causal = np.tril(np.ones((T, T)))
print("Causal matrix (1 = allowed, 0 = blocked):")
print(causal.astype(int))
# Convert to additive mask: 0 where allowed, -1e9 where blocked
mask = (1 - causal) * (-1e9)
print("\nAdditive mask (0 = pass through, -1e9 = block):")
print(mask)
# Simulate: random scores + mask + softmax
np.random.seed(7)
scores = np.random.randn(T, T) # raw attention scores
def softmax(x):
e = np.exp(x - x.max(axis=-1, keepdims=True))
return e / e.sum(axis=-1, keepdims=True)
masked_scores = scores + mask
attn_weights = softmax(masked_scores)
print("\nAttention weights after causal masking:")
print(np.round(attn_weights, 4))
print("\nRow sums:", np.round(attn_weights.sum(axis=1), 6))
print("\nNote: each row attends only to positions <= its own index.")En la salida, observa cómo la posición 0 pone todo su peso en sí misma (la única opción), mientras que la posición 4 distribuye la attention entre las cinco posiciones. El triángulo superior derecho es exactamente cero (no se filtra información del futuro).
Pensando en la attention como un grafo
Hay una forma de pensar en la matriz de attention que hace que el enmascaramiento causal se sienta menos como una restricción arbitraria y más como una estructura natural: tratar cada token como un nodo en un grafo dirigido , donde una arista del nodo $j$ al nodo $i$ significa "la posición $i$ atiende a la posición $j$" (la información fluye de $j$ a $i$). La matriz de pesos de attention $T \times T$ es exactamente la matriz de adyacencia ponderada de este grafo.
Sin ninguna máscara (attention bidireccional, como en un encoder como BERT), el grafo es completamente conectado: cada nodo tiene aristas hacia todos los demás nodos, incluyéndose a sí mismo. Para $T = 4$ tokens, eso son $4 \times 4 = 16$ aristas dirigidas. Cada token puede recopilar información de todos los demás tokens, que es exactamente lo que queremos cuando la entrada completa está disponible y estamos construyendo representaciones contextuales para tareas posteriores como clasificación o reconocimiento de entidades nombradas.
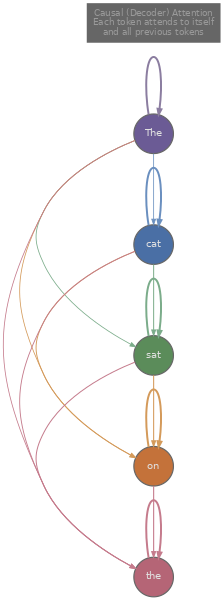
Con una máscara causal, el grafo es una matriz de adyacencia triangular inferior , y la conectividad se construye token por token. El token 0 tiene exactamente una arista (un bucle consigo mismo). El token 1 tiene dos aristas: hacia sí mismo y hacia el token 0. El token 2 tiene tres aristas: hacia los tokens 0, 1 y 2. En general, el token $i$ tiene exactamente $i + 1$ aristas. El número total de aristas es $1 + 2 + 3 + \cdots + T = T(T+1)/2$, aproximadamente la mitad de las aristas del caso completamente conectado.
Esta perspectiva de grafo hace concretas varias cosas. La cantidad de contexto disponible para un token aumenta linealmente con su posición: el primer token es el más escaso en información (solo se ve a sí mismo), mientras que el último token es el más rico en información (ve todo). Esta asimetría es inherente al modelado autoregresivo, y es una razón por la que la representación del primer token tiende a ser menos útil que la de los tokens posteriores en la práctica.
Podemos visualizar esto construyendo el grafo para una secuencia pequeña y comparando los casos causal y bidireccional.
import numpy as np
tokens = ["The", "cat", "sat", "on"]
T = len(tokens)
# Bidirectional (encoder): full connectivity
print("=== Bidirectional (Encoder) Attention ===")
print(f"Adjacency matrix ({T}x{T}, all ones):")
bi_adj = np.ones((T, T), dtype=int)
print(bi_adj)
print(f"Total edges: {bi_adj.sum()}")
print()
for i, tok in enumerate(tokens):
targets = [tokens[j] for j in range(T)]
print(f" '{tok}' (pos {i}) attends to: {targets}")
print()
# Causal (decoder): lower triangular
print("=== Causal (Decoder) Attention ===")
print(f"Adjacency matrix ({T}x{T}, lower triangular):")
causal_adj = np.tril(np.ones((T, T), dtype=int))
print(causal_adj)
print(f"Total edges: {causal_adj.sum()} (= T*(T+1)/2 = {T*(T+1)//2})")
print()
for i, tok in enumerate(tokens):
targets = [tokens[j] for j in range(i + 1)]
print(f" '{tok}' (pos {i}) attends to: {targets}")La salida muestra la diferencia estructural claramente. En el caso bidireccional, "The" en la posición 0 atiende a los cuatro tokens, incluyendo "on" en la posición 3. En el caso causal, "The" atiende solo a sí mismo, mientras que "on" en la posición 3 atiende a todos los tokens anteriores incluyéndose a sí mismo. La matriz de adyacencia pasa de ser una matriz de todos unos a una matriz triangular inferior, y cada estructura intermedia (como atender a todos los tokens dentro de una ventana fija, o atender a cada $k$-ésimo token) corresponde a un patrón de dispersión diferente en esta misma matriz $T \times T$.
El enfoque de grafo también clarifica el costo computacional. Cada arista en el grafo corresponde a un cálculo de score de attention (un producto punto entre un query y un key). La attention bidireccional calcula $T^2$ scores, la attention causal calcula $T(T+1)/2 \approx T^2/2$ scores, y los patrones de attention dispersa calculan aún menos. La dispersión del grafo se traduce directamente en ahorros computacionales, razón por la cual la investigación en attention eficiente (Tay et al., 2020) se enfoca fuertemente en encontrar buenas estructuras dispersas que preserven la calidad del modelo mientras reducen el costo $O(T^2)$.
Integrando todo: masked self-attention en la práctica
Ahora implementemos un paso completo de masked self-attention que combine todo lo de este artículo y el anterior: proyecciones query-key-value, productos punto escalados, enmascaramiento causal y la suma ponderada. Este es el cálculo central dentro de cada capa decoder de modelos como GPT-2, GPT-3 y LLaMA.
import numpy as np
np.random.seed(42)
def masked_self_attention(X, W_Q, W_K, W_V):
"""
Single-head causal self-attention.
X: (T, d_model) input embeddings
W_Q: (d_model, d_k) query projection
W_K: (d_model, d_k) key projection
W_V: (d_model, d_v) value projection
"""
T = X.shape[0]
d_k = W_Q.shape[1]
# Step 1: Project to Q, K, V
Q = X @ W_Q
K = X @ W_K
V = X @ W_V
# Step 2: Scaled dot-product scores
scores = (Q @ K.T) / np.sqrt(d_k)
# Step 3: Apply causal mask
mask = np.triu(np.ones((T, T)) * (-1e9), k=1)
scores = scores + mask
# Step 4: Softmax (row-wise)
e = np.exp(scores - scores.max(axis=-1, keepdims=True))
attn = e / e.sum(axis=-1, keepdims=True)
# Step 5: Weighted sum of values
output = attn @ V
return output, attn
# Setup
T, d_model, d_k, d_v = 5, 16, 8, 8
X = np.random.randn(T, d_model)
W_Q = np.random.randn(d_model, d_k) * 0.1
W_K = np.random.randn(d_model, d_k) * 0.1
W_V = np.random.randn(d_model, d_v) * 0.1
output, attn = masked_self_attention(X, W_Q, W_K, W_V)
print("Attention weights (causal, T=5):")
print(np.round(attn, 3))
print(f"\nOutput shape: {output.shape}")
print(f"\nPosition 0 sees only itself: weights = {np.round(attn[0], 3)}")
print(f"Position 4 sees all 5 positions: weights = {np.round(attn[4], 3)}")La salida confirma lo que esperamos: la posición 0 coloca todo su peso (1.0) en sí misma, porque la máscara causal bloquea todas las demás posiciones. La posición 4, al final de la secuencia, distribuye su attention entre las cinco posiciones según las similitudes aprendidas entre query y key. El triángulo superior de la matriz de attention es exactamente cero.
Vale la pena notar que la máscara en sí no tiene parámetros aprendidos. Es una restricción estructural fija determinada enteramente por las posiciones de la secuencia (el mismo patrón binario independientemente de cuáles sean los tokens). Todo el aprendizaje ocurre en $W^Q$, $W^K$ y $W^V$, que determinan cómo interactúan los tokens dentro de las conexiones permitidas. La máscara define la topología del grafo; las proyecciones definen los pesos de las aristas.
Ahora hemos cubierto los tres componentes centrales de la attention en transformers: el marco query-key-value (artículo 2), la fórmula del producto punto escalado (artículo 2) y la máscara causal (este artículo). Juntos, estos forman la subcapa de self-attention que se repite en cada bloque decoder del transformer. Los componentes restantes de una capa completa del transformer (attention multi-cabeza, conexiones residuales, normalización de capa y redes feed-forward) se construyen sobre esta base, y los cubriremos a medida que avancemos en la serie.
Quiz
Pon a prueba tu comprensión del enmascaramiento causal y la matriz de attention.
¿Por qué es necesario el enmascaramiento causal durante el entrenamiento, no solo durante la inferencia?
En una matriz de attention causal para una secuencia de T = 6 tokens, ¿cuántos pesos de attention no nulos hay en total?
Cuando sumamos -infinito a un score de attention antes del softmax, ¿cuál es el peso de attention resultante para esa posición?
En la interpretación de grafo, ¿a qué tipo de matriz de adyacencia corresponde la attention bidireccional (encoder)?