¿Por qué la atención no conoce el orden de las palabras?
La atención multi-head nos proporciona una forma poderosa para que los tokens se comuniquen, pero hay algo notablemente ausente en el mecanismo. Si tomamos una oración y barajamos el orden de los tokens, la salida de atención para cada token cambia (porque los values que promedia se han movido), pero los pesos de atención entre cualquier par de tokens permanecen idénticos. Esto se debe a que el producto punto $q_i^\top k_j$ depende únicamente del contenido de los tokens $i$ y $j$, no de dónde se encuentran en la secuencia. La atención es equivariante a permutaciones : permutar las filas de entrada permuta las filas de salida de la misma manera, sin que el mecanismo en sí sepa que ocurrió una permutación.
Esto es un problema porque el orden de las palabras transmite un significado enorme. "El perro mordió al hombre" y "El hombre mordió al perro" contienen las mismas palabras, pero significan cosas muy diferentes. Si alimentamos ambas oraciones a través de la atención sin ninguna señal posicional, el modelo no tiene forma de distinguir entre ellas (ya que cada puntuación token-a-token depende solo de qué son los tokens, no de dónde aparecen).
La solución de (Vaswani et al., 2017) es agregar un positional encoding al embedding de cada token antes de que entre en la primera capa de atención. Este encoding es un vector de la misma dimensión $d_{\text{model}}$ que depende únicamente de la posición del token en la secuencia. Al sumarlo al embedding de contenido, fusionamos "qué es este token" con "dónde se encuentra este token", y todos los cálculos de atención posteriores pueden usar ambas señales.
El transformer original usa un encoding determinístico basado en funciones sinusoidales. Para la posición $\text{pos}$ y la dimensión $i$, el encoding alterna entre seno y coseno con longitudes de onda exponencialmente crecientes.
Esta fórmula parece densa, pero la intuición se vuelve clara cuando examinamos qué ocurre en diferentes dimensiones. El denominador $10000^{2i/d_{\text{model}}}$ controla la longitud de onda: cuando $i = 0$ (el primer par de dimensiones), el denominador es $10000^0 = 1$, así que el seno y coseno oscilan a la velocidad más rápida (un ciclo completo cada $2\pi \approx 6.28$ posiciones). Cuando $i$ se acerca a $d_{\text{model}}/2$ (el último par), el denominador crece hasta $10000$, por lo que la onda se extiende a lo largo de aproximadamente 62,832 posiciones antes de completar un ciclo. Esto nos da un espectro que va desde ondas de alta frecuencia que distinguen tokens adyacentes hasta ondas de baja frecuencia que distinguen tokens separados por miles de posiciones.
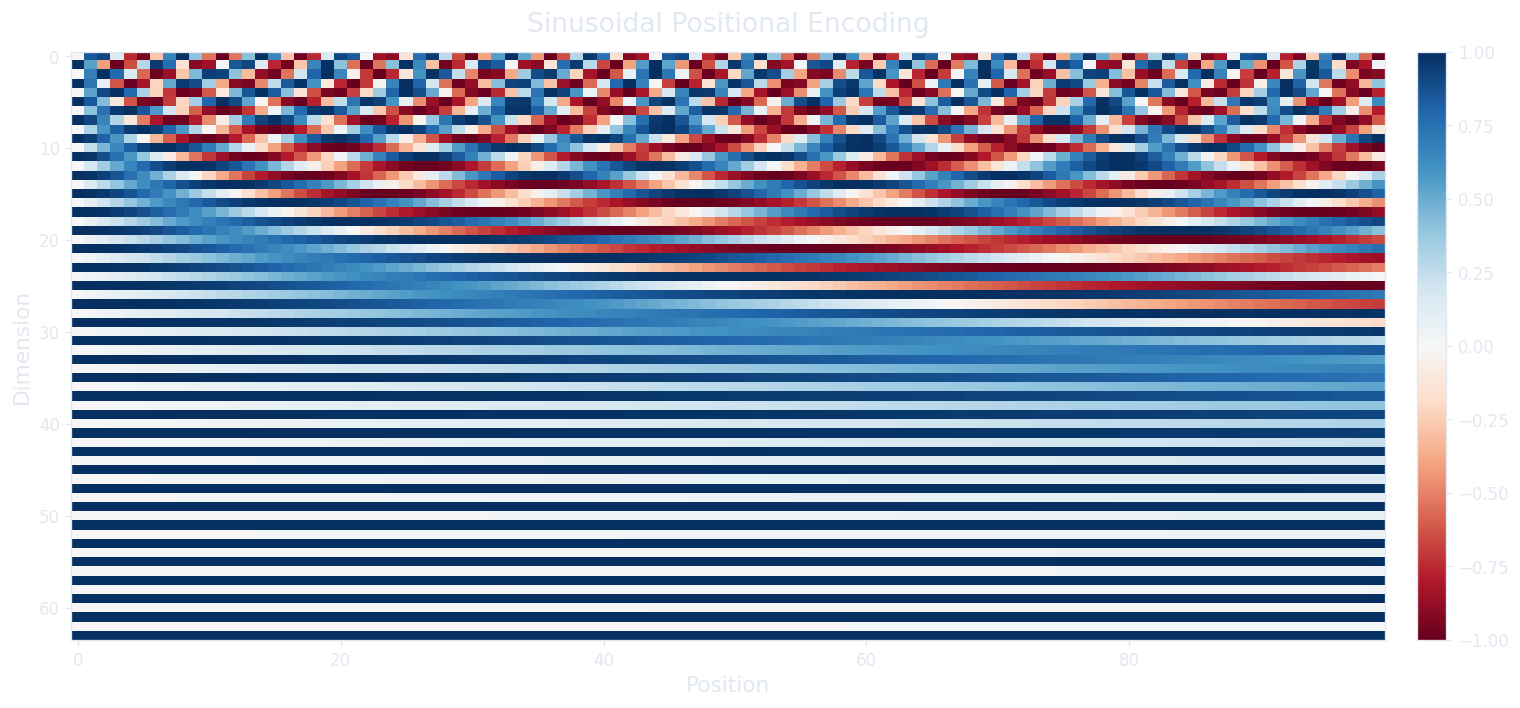
¿Por qué alternar seno y coseno? Porque para cualquier desplazamiento fijo $k$, el encoding en la posición $\text{pos} + k$ puede escribirse como una combinación lineal del encoding en la posición $\text{pos}$. Esta propiedad (que se deriva de la identidad trigonométrica $\sin(\alpha + \beta) = \sin\alpha \cos\beta + \cos\alpha \sin\beta$) significa que el modelo puede aprender a atender a posiciones relativas mediante transformaciones lineales de los queries y keys. Si hubiéramos usado solo seno (o solo coseno), perderíamos esto: una sola sinusoide a una frecuencia dada no permite recuperar de forma única el desplazamiento mediante una operación lineal.
¿Cómo evitan los transformers profundos el desvanecimiento de gradientes?
Ahora tenemos una capa de atención multi-head enriquecida con información posicional. Un siguiente paso natural es apilar muchas de estas capas para construir un modelo profundo, ya que las redes más profundas tienden a aprender representaciones más ricas. Pero apilar capas de forma ingenua crea un problema bien conocido: durante la retropropagación, el gradiente debe fluir a través de la transformación de cada capa, y el jacobiano de cada capa se multiplica en la cadena. Si esos jacobianos tienen consistentemente valores propios menores que 1, el gradiente se reduce exponencialmente con la profundidad y las capas iniciales dejan de aprender. Este es el problema del desvanecimiento de gradientes , y afectó a las redes profundas mucho antes de los transformers.
La solución, tomada de ResNets (He et al., 2015) , es una conexión residual : en lugar de calcular $\text{output} = f(x)$, calculamos $\text{output} = x + f(x)$. El gradiente de $x + f(x)$ con respecto a $x$ es $I + \frac{\partial f}{\partial x}$, donde $I$ es la identidad. Incluso si $\frac{\partial f}{\partial x}$ es pequeño, el término de identidad garantiza un gradiente de al menos 1 fluyendo directamente. Esto crea lo que podemos considerar una "autopista de gradientes" que evita por completo la transformación de la capa, permitiendo que la señal llegue a las capas iniciales sin atenuación.
También existe una perspectiva elegante sobre lo que esto significa para el aprendizaje. Sin la conexión residual, cada capa debe aprender la transformación completa de la entrada a la salida deseada. Con la conexión residual, cada capa solo necesita aprender el residual (el delta, la corrección, la diferencia entre la entrada y la salida deseada). Si la función óptima está cerca de la identidad (lo cual ocurre frecuentemente en capas más profundas, donde las representaciones ya han sido refinadas), la capa puede aprender a producir una salida cercana a cero, pasando efectivamente la entrada sin cambios. Aprender "no hacer casi nada" es mucho más fácil para una red neuronal que aprender un mapeo de identidad completo, y esto hace que la optimización sea más suave a través de muchas capas.
En el transformer, las conexiones residuales envuelven tanto la subcapa de atención como la subcapa feed-forward. Cada bloque toma su entrada, la procesa a través de la subcapa y suma el resultado de vuelta a la entrada original.
¿Dónde encaja la layer normalization?
Las conexiones residuales resuelven el problema del flujo de gradientes, pero introducen otro problema: dado que cada capa suma su salida al acumulado, la magnitud de las activaciones puede crecer con la profundidad. Después de 12 capas de sumas, los estados ocultos podrían tener normas mucho mayores que los embeddings iniciales, y esta deriva de escala puede desestabilizar el entrenamiento (activaciones grandes llevan a gradientes grandes, que llevan a actualizaciones de pesos grandes, que llevan a activaciones aún mayores).
La layer normalization (Ba et al., 2016) aborda esto normalizando las activaciones dentro de la representación de cada token. Para un vector $\mathbf{x}$ de dimensión $d_{\text{model}}$, calculamos la media $\mu$ y la varianza $\sigma^2$ a través de las dimensiones, normalizamos, y aplicamos parámetros aprendibles de escala ($\gamma$) y desplazamiento ($\beta$).
El término $\epsilon$ (típicamente $10^{-5}$) previene la división por cero cuando la varianza es muy pequeña, y los parámetros aprendibles $\gamma$ y $\beta$ permiten al modelo deshacer la normalización si eso resulta útil (le dan a la capa la expresividad para aprender la función identidad a través de la normalización si es necesario).
Una decisión arquitectónica importante es dónde colocar la normalización en relación con la subcapa. El paper original del transformer (Vaswani et al., 2017) usó post-norm : primero calcular la subcapa, sumar el residual, luego normalizar. Esto significa que la normalización actúa sobre la suma $x + \text{Sublayer}(x)$.
La mayoría de los transformers modernos (GPT-2, GPT-3, LLaMA, y muchos otros) usan pre-norm en su lugar: normalizar primero, luego aplicar la subcapa, luego sumar el residual. Xiong et al. (2020) ("On Layer Normalization in the Transformer Architecture") mostraron que pre-norm tiende a producir gradientes más estables en la inicialización, lo que facilita el entrenamiento (especialmente para modelos más profundos) y a menudo elimina la necesidad de un programa cuidadoso de calentamiento de la tasa de aprendizaje.
¿Por qué el transformer necesita una red feed-forward?
En este punto tenemos atención (enriquecida con información posicional), conexiones residuales y layer normalization. Si apiláramos solo capas de atención, ¿sería suficiente? La atención permite que los tokens recopilen información de otros tokens, pero no existe un mecanismo para que un token transforme su propia representación a través de una función no lineal después de haber recopilado esa información. Cada paso hasta ahora ha sido una proyección lineal o un promedio ponderado por softmax, y apilar operaciones lineales produce otra operación lineal. Sin una no linealidad, la expresividad de la red se estancaría independientemente de la profundidad.
La red feed-forward por posición (FFN) llena este vacío. Consiste en dos transformaciones lineales con una no linealidad entre ellas, aplicadas independientemente a cada token.
Aquí $W_1$ tiene forma $(d_{\text{model}}, d_{\text{ff}})$ y $W_2$ tiene forma $(d_{\text{ff}}, d_{\text{model}})$, donde $d_{\text{ff}}$ es típicamente $4 \times d_{\text{model}}$. El paper original usó ReLU como $\sigma$; muchos modelos modernos usan GELU (Hendrycks & Gimpel, 2016) o SwiGLU (Shazeer, 2020) en su lugar, que tienden a entrenar de forma más suave.
Recorramos las formas para entender la expansión y compresión. Si $d_{\text{model}} = 512$ y $d_{\text{ff}} = 2048$, entonces $W_1$ proyecta cada token de 512 dimensiones a 2048 (expandiendo la representación 4 veces), la no linealidad se aplica elemento a elemento, y $W_2$ proyecta de vuelta de 2048 a 512. Esta arquitectura de cuello de botella (expandir, transformar, comprimir) le da a la red un espacio de alta dimensión en el cual realizar computación no lineal, y luego comprime el resultado de vuelta a $d_{\text{model}}$ para que pueda alimentar la siguiente capa.
¿Qué se rompería si elimináramos $\sigma$? Sin la no linealidad, $W_2 (W_1 x + b_1) + b_2$ colapsa en una sola transformación afín $Ax + b$ (ya que la composición de dos mapeos lineales es lineal). Dos capas de parámetros no ofrecerían más poder expresivo que una. La no linealidad es lo que permite a la FFN aprender funciones que la atención sola no puede representar. ¿Y si $d_{\text{ff}}$ fuera igual a $d_{\text{model}}$ en lugar de $4 \times d_{\text{model}}$? La red aún podría aplicar transformaciones no lineales, pero en un espacio de menor dimensión, limitando la variedad de características que puede extraer. Empíricamente, la expansión de 4x logra un equilibrio entre capacidad y cantidad de parámetros; proporciones menores tienden a perjudicar el rendimiento mientras que las mayores muestran rendimientos decrecientes.
Hay una distinción arquitectónica clave entre la atención y la FFN que vale la pena enfatizar. La atención es un mecanismo de comunicación : mueve información entre tokens (o, en términos de grafos, pasa mensajes entre nodos). La FFN es un mecanismo de computación : transforma la representación de cada token de forma independiente, sin interacción entre posiciones. Esto significa que la FFN en la posición 5 no tiene idea de cómo luce el token en la posición 3 (procesa el vector en la posición 5 en completo aislamiento). Todo el intercambio de información entre tokens debe ocurrir a través de la atención; el trabajo de la FFN es procesar lo que la atención recopiló.
Trabajo reciente ha sugerido que las capas FFN actúan como una forma de memoria clave-valor, donde $W_1$ almacena patrones aprendidos (claves) y $W_2$ almacena la salida asociada (valores). Geva et al. (2021) ("Transformer Feed-Forward Layers Are Key-Value Memories") mostraron que las neuronas individuales en la primera capa a menudo se activan ante patrones de entrada interpretables (palabras específicas, estructuras sintácticas o categorías semánticas), y las columnas correspondientes de $W_2$ tienden a promover distribuciones predecibles del siguiente token. En esta perspectiva, la FFN es donde el transformer almacena conocimiento factual, mientras que la atención es cómo enruta y compone ese conocimiento.
¿Cómo luce un bloque completo del transformer?
Ahora podemos ensamblar todas las piezas en un solo bloque del transformer. Cada bloque aplica dos subcapas (atención multi-head y una red feed-forward), cada una envuelta en una conexión residual y layer normalization. Usando el ordenamiento pre-norm (la convención moderna), un bloque toma la entrada $x$ y produce la salida $x'$ de la siguiente manera.
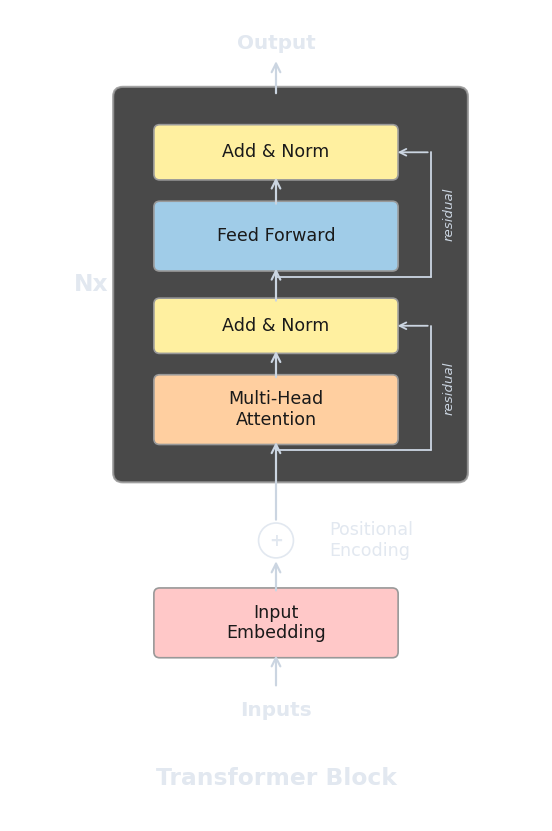
La siguiente implementación reúne todos nuestros componentes en un bloque completo de transformer pre-norm, incluyendo la clase de atención multi-head del artículo anterior.
import torch
import torch.nn as nn
import json, js
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.W_Q = nn.Linear(d_model, d_model, bias=False)
self.W_K = nn.Linear(d_model, d_model, bias=False)
self.W_V = nn.Linear(d_model, d_model, bias=False)
self.W_O = nn.Linear(d_model, d_model, bias=False)
def forward(self, x, mask=None):
B, T, C = x.shape
Q = self.W_Q(x).view(B, T, self.num_heads, self.d_k).transpose(1, 2)
K = self.W_K(x).view(B, T, self.num_heads, self.d_k).transpose(1, 2)
V = self.W_V(x).view(B, T, self.num_heads, self.d_k).transpose(1, 2)
scores = (Q @ K.transpose(-2, -1)) / (self.d_k ** 0.5)
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
attn = F.softmax(scores, dim=-1)
out = (attn @ V).transpose(1, 2).contiguous().view(B, T, C)
return self.W_O(out)
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff):
super().__init__()
self.W1 = nn.Linear(d_model, d_ff)
self.W2 = nn.Linear(d_ff, d_model)
def forward(self, x):
return self.W2(F.gelu(self.W1(x)))
class TransformerBlock(nn.Module):
"""Pre-norm transformer block: LN -> Attention -> residual -> LN -> FFN -> residual"""
def __init__(self, d_model, num_heads, d_ff):
super().__init__()
self.ln1 = nn.LayerNorm(d_model)
self.attn = MultiHeadAttention(d_model, num_heads)
self.ln2 = nn.LayerNorm(d_model)
self.ffn = FeedForward(d_model, d_ff)
def forward(self, x, mask=None):
# Sublayer 1: attention with pre-norm and residual
x = x + self.attn(self.ln1(x), mask)
# Sublayer 2: FFN with pre-norm and residual
x = x + self.ffn(self.ln2(x))
return x
# --- Verify shapes and parameter counts ---
d_model = 512
num_heads = 8
d_ff = 2048 # 4x expansion
T = 10
batch = 2
block = TransformerBlock(d_model, num_heads, d_ff)
x = torch.randn(batch, T, d_model)
out = block(x)
print(f"Input shape: {x.shape}")
print(f"Output shape: {out.shape}")
print()
# Count parameters by component
attn_params = sum(p.numel() for p in block.attn.parameters())
ffn_params = sum(p.numel() for p in block.ffn.parameters())
ln_params = sum(p.numel() for p in block.ln1.parameters()) + \
sum(p.numel() for p in block.ln2.parameters())
total = sum(p.numel() for p in block.parameters())
js.window.py_table_data = json.dumps({
"headers": ["Component", "Parameters", "Share"],
"rows": [
["Attention", f"{attn_params:,}", f"{attn_params/total:.1%}"],
["FFN", f"{ffn_params:,}", f"{ffn_params/total:.1%}"],
["LayerNorm", f"{ln_params:,}", f"{ln_params/total:.1%}"],
["Total", f"{total:,}", "100.0%"],
]
})
Observa cómo el método
TransformerBlock.forward
tiene solo cuatro líneas. Las primeras dos aplican atención pre-norm con una conexión residual, y las segundas dos hacen lo mismo para la FFN. Esta simplicidad es una de las propiedades más atractivas del transformer: cada capa tiene exactamente la misma estructura, las formas de entrada y salida son idénticas, y apilar $N$ capas es simplemente un bucle. La arquitectura completa de GPT-2, por ejemplo, es una capa de embedding, 12 (o 24, o 48) copias de este bloque, una layer norm final y una cabeza lineal.
Los conteos de parámetros impresos arriba confirman nuestra observación anterior sobre el dominio de la FFN. Con el factor de expansión estándar de $4 \times$, la FFN representa aproximadamente dos tercios de los parámetros de cada bloque, mientras que la atención representa alrededor de un tercio. Esta proporción se mantiene independientemente de $d_{\text{model}}$, ya que ambos componentes escalan como $O(d_{\text{model}}^2)$.
Quiz
Pon a prueba tu comprensión de los componentes que completan el bloque del transformer.
¿Por qué el transformer necesita positional encodings?
¿Cuál es el gradiente de x + f(x) con respecto a x, y por qué esto ayuda con redes profundas?
¿Cuál es la diferencia clave entre la atención y la red feed-forward en términos de cómo procesan los tokens?
En los transformers pre-norm, ¿dónde se aplica LayerNorm en relación con la subcapa y la conexión residual?
¿Por qué la FFN se expande a 4x d_model antes de comprimir de vuelta?