Why Would a Single Head Fall Short?
By now we have a complete single-head attention mechanism: queries and keys produce a score matrix, we scale by $\sqrt{d_k}$, apply softmax, and use the result to weight the values. That mechanism works, but it forces every token to summarize everything it needs from the sequence into a single attention pattern. Consider the word "bank" in the sentence "The bank by the river issued a statement." To understand this sentence, "bank" needs to attend to "river" (to resolve that this is a riverbank, not a financial institution) and simultaneously attend to "issued" (to pick up that the subject of the verb is "bank"). A single attention distribution is a probability distribution over positions, so the attention weights must sum to 1, and focusing heavily on "river" necessarily takes weight away from "issued."
This is not a contrived edge case. Language constantly requires tracking multiple relationships at once: syntactic dependencies (what is the subject of this verb?), semantic similarity (which words share meaning?), coreference (which noun does this pronoun refer to?), and positional proximity (what came right before this word?). A single attention head compresses all of these into one weighted average, which forces the model to compromise between competing demands.
The fix proposed in (Vaswani et al., 2017) is to run several attention heads in parallel, each with its own learned projections, so that different heads can specialize in different types of relationships. The outputs are then concatenated and projected back to the model dimension. This is multi-head attention .
How Does the Model Split Into Multiple Heads?
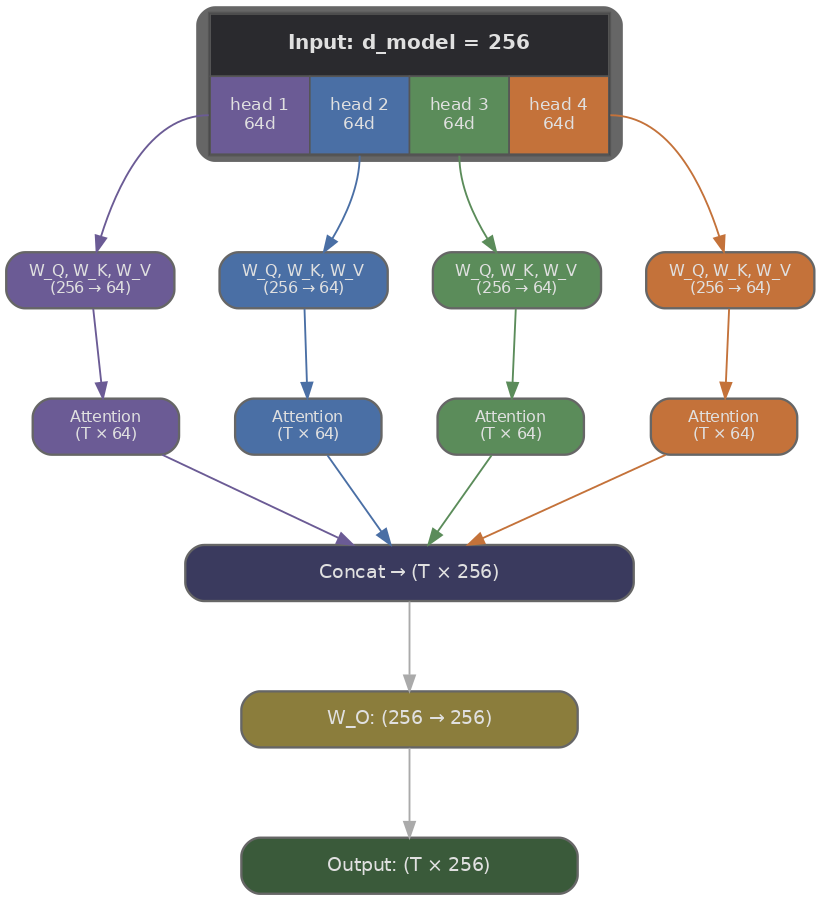
Suppose our model dimension is $d_{\text{model}} = 512$ and we want $H = 8$ heads. Rather than giving each head its own full-sized projections (which would multiply the parameter count by 8), we split the representation: each head operates on a slice of size $d_k = d_{\text{model}} / H = 64$. The total computation stays roughly the same as single-head attention over the full $d_{\text{model}}$, because we run $H$ smaller attentions instead of one large one.
Each head $i$ has its own projection matrices $W_i^Q$, $W_i^K$, and $W_i^V$, each of shape $(d_{\text{model}}, d_k)$. Given an input $X$ of shape $(T, d_{\text{model}})$ where $T$ is the sequence length, the projections for head $i$ are computed as follows.
Each head then runs standard scaled dot-product attention independently, producing an output of shape $(T, d_k)$. Since there are $H$ heads, we get $H$ outputs of shape $(T, d_k)$, which we concatenate along the last dimension to recover shape $(T, d_{\text{model}})$. A final output projection $W^O$ of shape $(d_{\text{model}}, d_{\text{model}})$ mixes information across heads.
Let's trace the shapes through a concrete example with $d_{\text{model}} = 512$, $H = 8$, $d_k = 64$, and a sequence of $T = 10$ tokens:
- Input: $X$ is $(10, 512)$.
- Per-head projection: $Q_i = X W_i^Q$ maps $(10, 512) \times (512, 64) \to (10, 64)$. Same for $K_i$ and $V_i$.
- Per-head attention scores: $Q_i K_i^\top$ maps $(10, 64) \times (64, 10) \to (10, 10)$. Each head produces its own $T \times T$ attention matrix.
- Per-head output: $\text{softmax}(\ldots) \, V_i$ maps $(10, 10) \times (10, 64) \to (10, 64)$.
- Concatenation: stack all 8 heads along the last axis: $(10, 64) \times 8 \to (10, 512)$.
- Output projection: $W^O$ maps $(10, 512) \times (512, 512) \to (10, 512)$.
The output has exactly the same shape as the input, $(T, d_{\text{model}})$, which means multi-head attention is a drop-in replacement for single-head attention. This shape-preserving property also matters for stacking layers, since the output of one attention block becomes the input to the next.
What Does This Look Like in Code?
In practice, we don't loop over heads one by one. Instead, we project the full $d_{\text{model}}$ for all heads at once using a single weight matrix of shape $(d_{\text{model}}, d_{\text{model}})$, then reshape the result to separate the heads. This is mathematically identical to having $H$ separate $(d_{\text{model}}, d_k)$ projections, but it runs in one matrix multiply instead of $H$, which is much faster on GPUs.
The following implementation keeps things explicit so we can see each step clearly. We project all heads at once, reshape to split them, run attention per head, concatenate, and apply the output projection.
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
# One big projection for all heads, then we reshape
self.W_Q = nn.Linear(d_model, d_model, bias=False)
self.W_K = nn.Linear(d_model, d_model, bias=False)
self.W_V = nn.Linear(d_model, d_model, bias=False)
self.W_O = nn.Linear(d_model, d_model, bias=False)
def forward(self, X, mask=None):
B, T, _ = X.shape # batch, sequence length, d_model
# Project all heads at once: (B, T, d_model) -> (B, T, d_model)
Q = self.W_Q(X)
K = self.W_K(X)
V = self.W_V(X)
# Reshape to (B, num_heads, T, d_k) so each head has its own slice
Q = Q.view(B, T, self.num_heads, self.d_k).transpose(1, 2)
K = K.view(B, T, self.num_heads, self.d_k).transpose(1, 2)
V = V.view(B, T, self.num_heads, self.d_k).transpose(1, 2)
# Scaled dot-product attention per head
# scores: (B, num_heads, T, T)
scores = (Q @ K.transpose(-2, -1)) / (self.d_k ** 0.5)
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
attn_weights = F.softmax(scores, dim=-1)
# Weighted sum of values: (B, num_heads, T, d_k)
head_outputs = attn_weights @ V
# Concatenate heads: (B, T, d_model)
concat = head_outputs.transpose(1, 2).contiguous().view(B, T, self.d_model)
# Final projection mixes information across heads
return self.W_O(concat)
# --- Quick shape check ---
d_model, num_heads, T, batch = 512, 8, 10, 2
mha = MultiHeadAttention(d_model, num_heads)
X = torch.randn(batch, T, d_model)
output = mha(X)
print(f"Input shape: {X.shape}") # (2, 10, 512)
print(f"Output shape: {output.shape}") # (2, 10, 512)
print(f"Heads: {num_heads}, head dim: {d_model // num_heads}")
print(f"Parameters: {sum(p.numel() for p in mha.parameters()):,}")
A few things to notice in the code. The
view
and
transpose
calls are the key operations:
view(B, T, num_heads, d_k)
splits the last dimension into separate heads, and
transpose(1, 2)
moves the head dimension before the sequence dimension so that the batch matrix multiply
Q @ K.transpose(-2, -1)
runs attention independently for each head in parallel. After attention, we reverse the operation with
transpose(1, 2).contiguous().view(B, T, d_model)
to concatenate the heads back together.
What Do Different Heads Actually Learn?
Nothing in the architecture forces heads to specialize, yet empirically they tend to. Several studies have analyzed what patterns emerge in trained transformers, and the findings are remarkably consistent.
Clark et al. (2019) analyzed BERT's attention heads and found that individual heads often learn interpretable roles. Some heads track syntactic dependencies (the head consistently attends from a verb to its subject, regardless of distance), while others focus on positional patterns (attending to the previous token or the next token). Voita et al. (2019) ("Analyzing Multi-Head Self-Attention") went further and identified three dominant head types in English-to-Russian translation models: positional heads (attending to an adjacent position), syntactic heads (attending along dependency parse edges), and rare-word heads (attending to the least frequent tokens in the sentence, which tend to carry the most disambiguating information).
This specialization is why multi-head attention outperforms simply increasing $d_k$ in a single head. A larger single head has more capacity, but it still produces one attention pattern per token. Multiple heads allow the model to route different types of information through different channels simultaneously, and the output projection $W^O$ learns to combine them. In graph-theoretic terms (recalling our earlier framing of the attention matrix as an adjacency matrix), each head defines a different graph over the same set of tokens, and the model reads all of these graphs at once.
Quiz
Test your understanding of multi-head attention and how it extends the single-head mechanism.
If d_model = 768 and we use 12 attention heads, what is the dimension of each head's query, key, and value vectors?
Why does multi-head attention use an output projection W_O after concatenating the heads?
What is the main advantage of multi-head attention over single-head attention with the same d_model?
How does the total parameter count of multi-head attention compare to single-head attention (assuming the same d_model)?